Прежде чем мы начнем формировать таблицу связей, нам нужно привести таблицы модели данных в соответствие к следующим требованиям:
- Имена полей, которые будут использоваться для связи (поля дат в них не входят), одинаковые между всеми таблицами;
- Связи должны быть построены по единообразной структуре (если в одной таблице используются ИД сотрудников, в в другой их имена, то имена нужно заменить на ИД сотрудников);
- Имена полей, которые не будут использоваться для связи, должны иметь уникальное название на уровне всей модели;
- Поля дат, планируемые к использованию в едной временной оси, должны быть приведены ко дню (date, а не timestamp). Даты, которые относятся к агрегированным периодам должны быть приведены к первой дате этого периода (не январь 2021, а 01.01.2021. Не Q2 2022, а 01.04.2022)
Начнем же.
Управление именами полей в модели данных
Первый способ назначить имя полю — задать его в явном виде, через команду as.
Нам нужно переименовать поле «Contact ID» в «ID контакта» в загрузке таблицы контактов. И поле «ID сотрудника» в «ID ответственного» в загрузке справочника сотрудников.
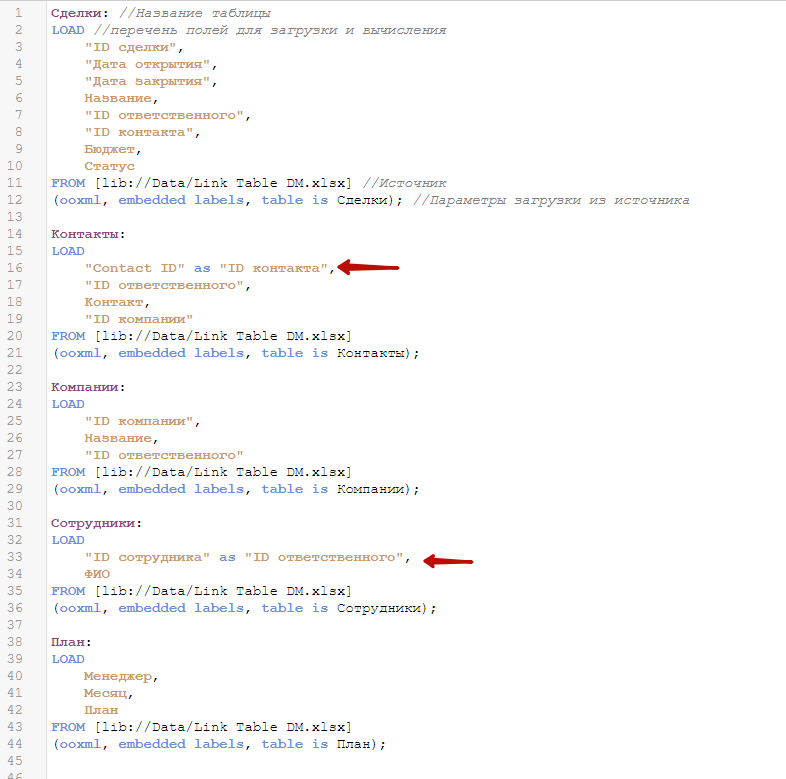
Перезагрузим данные. Синтетические ключи никуда не делись, они стали даже еще страшнее. А таблица План по-прежнему летает в воздухе. Но, всему свое время.
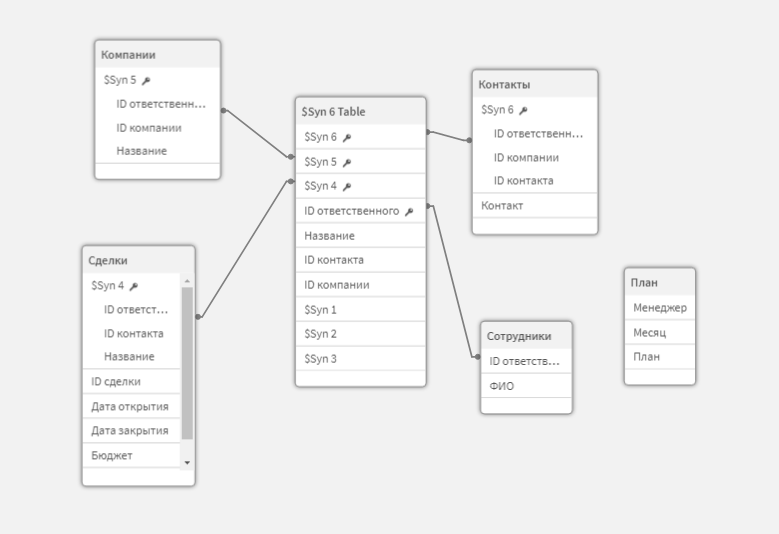
Подмена значений поля через сопоставление
Чтобы таблица План могла быть задействована в модели, нам нужно решить вопрос с добавлением в нее ключевых полей. В ней есть поле Менеджер. Но оно содержит имя сотрудника. А у нас связь с сотрудниками должна идти через справочник Сотрудники. По идее, надо преобразовать имена сотрудников в Таблице план в идентификаторы сотрудников из таблицы Соттрудники.
Добавим в самом верху вкладки вот такую конструкцию. С помощью команды mapping перед оператором load, мы загружаем пары значений ФИО — ID отстветственного из справочника сотрудников в качестве таблицы сопоставления (маппинг).
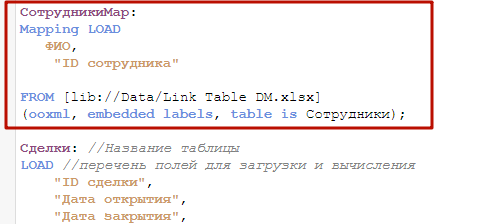
В таких таблицах может быть не больше 2-х столбцов. Первый столбец — значения которые мы проверям, второй — на что меняем совпавшее заначение. Наименование полей не важен — поиск будет происходить именно по значениям полей.
Таблица сопоставлний не является частью модели данных и автоматически удаляется после завершения скрипта.
После создания маппинг можно применить в любой другой таблице. Поэтому обычно маппинги создаются в начале скрипта.
Применяется маппинг через функцию applymap(), которая имеет до 3-х аргументов:
- Название применяемого маппинга в одинарных кавычках;
- Значение, к которому применяется маппинг;
- Опционально — значение, которое проставляется в случае отсутствия совпадений. Если не указано, будет подставлено оригинальное название поля из второго аргумента. Также тут можно указывать функции, например применение следующего маппинга, и т.д.

Применяем наш маппинг в таблице планов к полю Менеджер, и не забываем назвать итоговое поле «ID ответственного». Загружаем данные. Теперь все таблицы связаны. Синтетический ключ, конечно же, на месте.
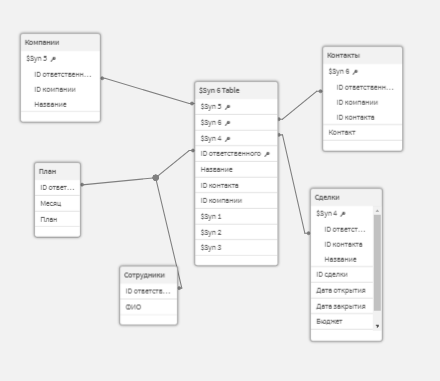
Массовая уникализация имен
С полями связей разобрались. Теперь, нужно исключить связи по не нужным полям, например таким как Название. В нашем примере мало полей, и переименовать их через as не составило бы труда. Но в реальной жизни модели будут наверняка сложнее. Больше полей, больше таблиц. Добавление полей в уже имеющиеся таблицы.
Все это делает ручную уникализацию довольно утомительной. А с выборочным переименованием полей вы рискуете однажды добавить в таблицу поле, которое совпадет с полем из другой таблицы, и ваша модел рассыпется как карточный домик.
В Qlik есть несколько способов автоматического переименования полей. Самая простая — это квалификация (функция qualify).
Эта функция вызывается между загрузками таблиц. После нее прописывается перечень имен полей, которые мы хотим квалифицировать. Квалификация подписывает к названию поля префикс в виде названия таблицы. Таким образом, достигается уникльность названия поля.
Поля для квалификации можно прописывать не только в явном виде, но и с использованием знаков подстановки символов, например *. Звездой можно заменить часть имени поля, или вообще все поля.
Qualify *; будет производить переименование всех полей в модели данных, что равноценно разрыву связей между всеми таблицами. Пропишите Qualify *; в начале вкладки Данные, и выполните скрипт.
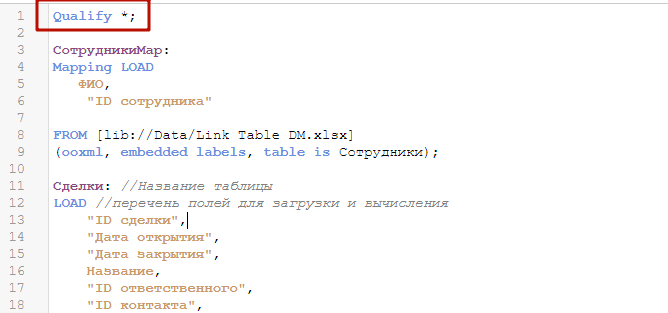
Посмотрите в модель данных. Синтетических ключей нет, правда связей тоже нет. Все поля имеют префикс в виде названия таблицы, и как следствие все поля уникальны во всей модели.

Конечно, нас не устроит такой результат. Поэтому вместе с Qualify, мы будем использовать команду Unqualify. Эта команда исключает названные поля из списка квалификации.
После Qualify *; пропишите Unqualify «ID*»;
Это исключит из квалификации все поля, названия которых начинаются с ID. Конкретно этот способ подходит для нашего дата-сета, потому что мы познакомились об однообразии названий ключевых полей.
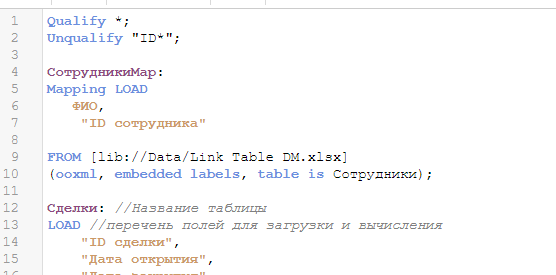
Действие квалификации продолжается до тех пор, пока не останавливается командой Unqualify *; Важно прописать ее в конце загрузки данных, т.к. мы не хотим, чтобы квалификация вмешивалась в построение таблицы связей, в которой мы будем оперировать полями из ранее загруженных таблиц.
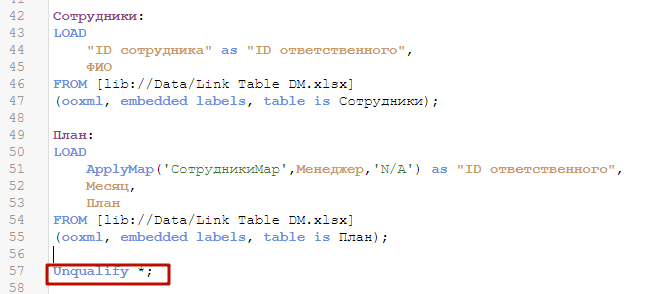
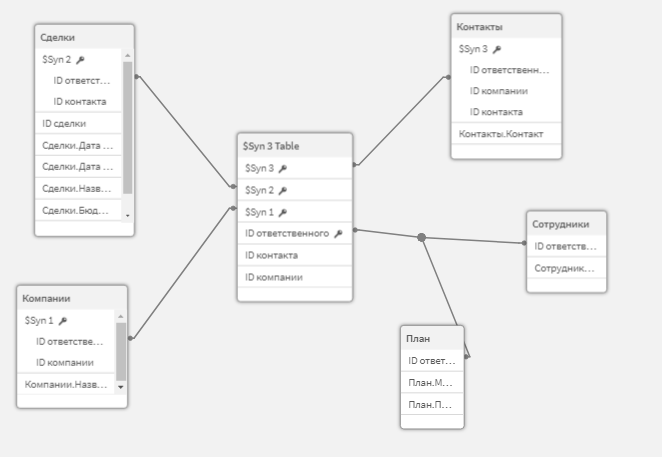
Загрузите данные. Синтетический ключ вернулся, но теперь мы точно знаем, что у нас правильно размечены ключевые поля, и в них нет ничего лишнего.
Нормализация полей дат
Прежде чем мы перейдем к сборке таблицы связей, причешем поля дат для будущей единой временной оси. Как проверить, что с датами все ок? У этих полей должен стоять тег $date, который видно в просмотре модели данных.
Зайдем в просмотр модели, и поглядим на теги поля Сделки.Дата открытия.
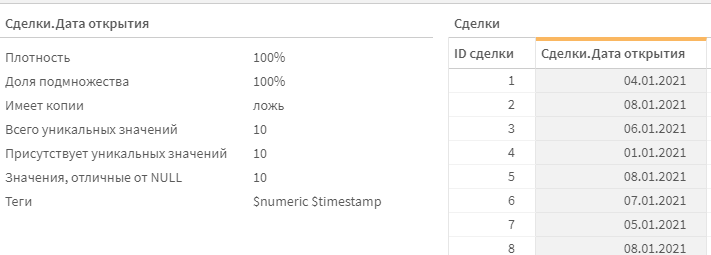
В значениях поля мы видим даты. Но в тегах есть только $numeric и $timestamp. Это коварная ловушка источника данных, который подсовывает клику не тот формат данных, который по факту содержится в ячейке. На самом деле это не даты, а таймстампы, отформатированные как даты.
Т.е. 01.01.2021 12:45:51, которые показываются как 01.01.2021.
Вообще клик использует такой же формат чисел, как и Excel, и Google Sheets. Т.е. число 44 285,69 при форматировании в timestamp вернет нам такую метку времени: 30.03.2021 16:42:44.
Целая часть числа является счетчиком дней с 31.12.1899 года. Дробная часть числа — это время суток, где 0,5 — это 12 часов дня.
То, что у нас в данных именно таймстамп — это хорошо, но его нужно округлить до целого дня, чтобы дробной части не было.
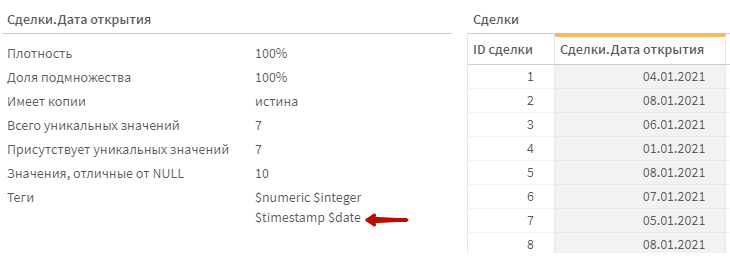
Этот результат можно получить через функцию floor() — она округляет до целого числа в меньшую сторону. Дополнительно, обернем это в функцию date(), которая форматирует входное число как дату — чтобы у нас на выходе были даты, а не значения типа 44165. Не забываем задать название этому полю.

Загружаем данные и смотрим в модель. У этого поля должен появиться тег $date. Тег $timestamp также никуда не исчезает, но это нормально. В конце концов, каждая дата может быть отформатирована как метка времени вроде 01.01.2021 00:00:00
Теперь посмотрим на поле Сделки.Дата закрытия. Вот сюрприз, оказывается даты в этом поле вовсе не даты, а текст! Это чревато для нас тем, что мы не сможем применить к этому значению функции по трансформации дат, например в месяцы и годы. Да и вообще с таким полем все будет работать не правильно.
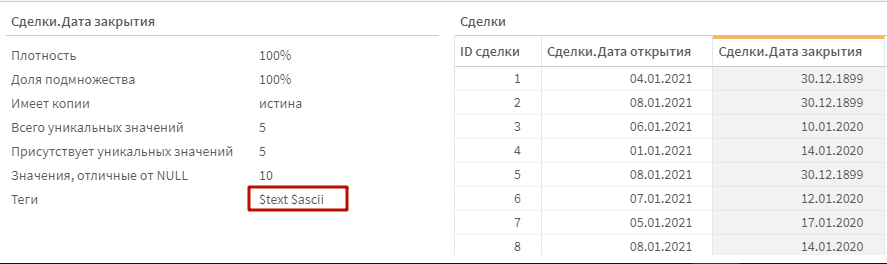
Чтобы преобразовать текст в дату, нужно использовать функцию интерпретации, а именно date#(). Вообще у каждой функции формата, вроде num(), time(), timestamp() есть парная функция интерпретации с решеткой. Функции интерпретации позволяют преобразовать значения текста в число, на основе совпадения по маске.
Даты в поле Дата закрытия опеределнно соовтетствуют маске DD.MM.YYYY. Вдобавок, обернем эту конструкцию в функцию Date, чтобы получилось:
date(date#("Дата закрытия",'DD.MM.YYYY')) as "Дата закрытия",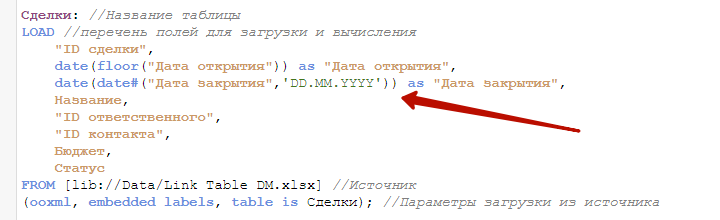
Проверим наше поле. Чтож, оно стало числовым, но все еще без тега $date, хотя это точно даты.
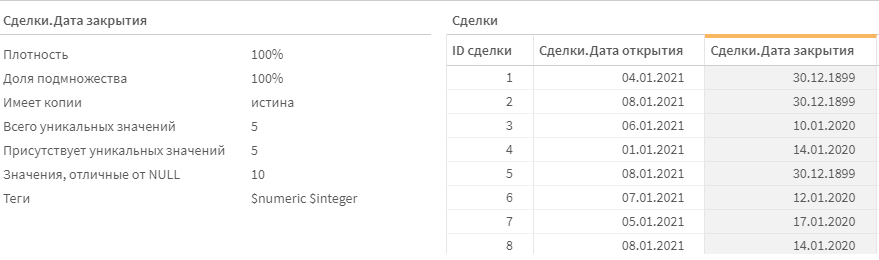
Возможно вы заметили, что у нас там присутствуют интересные даты — 30.12.1899. Так выглядит число 0, представленное в виде даты. Дело в том, что это поле заполняется только при закрытии сделки. Соответственно у открытых сделок даты закрытия нет. В зависимости от источника, там могут содержаться или пустые значения, или что-нибудь тезническое типа 0.
От таких значений нужно избавляться, посколько они будут засорять временную ось, а при определенных условиях могут многократно увеличить ресурсы, потребляемые приложением. Избавиться от этих значений можно через замену их на null.
Это можно сделать через формулу с if, приравняв ненужные значения к функции null(). Либо прописав if так, чтобы дата расчитывалась только для нужных значений.
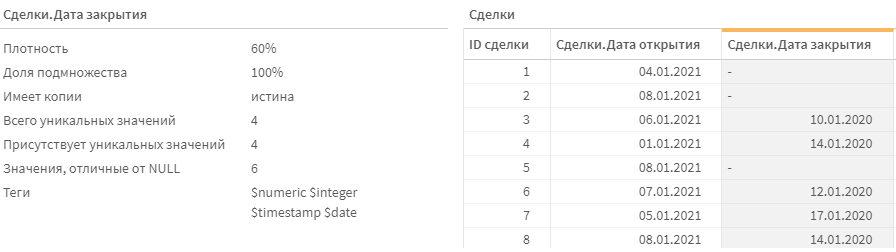
if("Дата закрытия"<>'30.12.1899',date(date#("Дата закрытия",'DD.MM.YYYY'))) as "Дата закрытия"
Результат: часть дат отмечена как прочерки (именно так отображаются пустые значения, которые null). Поле получило тег $date.
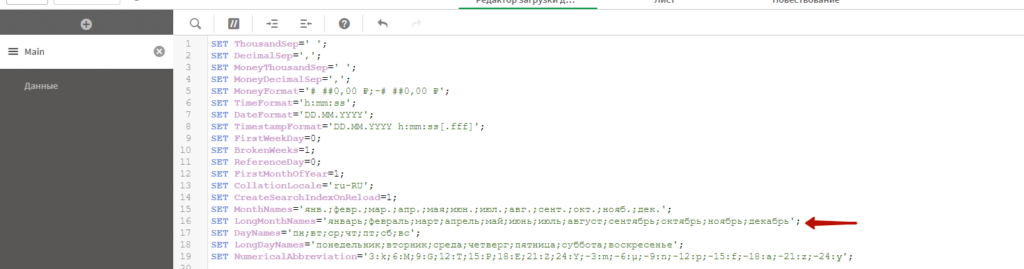
Напоследок, разберемся с датами в поле План.Месяц. Когда даты приходят в таком формате, остается лишь сказать «Спасибо, что хоть год подписали».

Преобразование дат из такого прям строкового текста может быть выоплнено большим кол-вом способов. С маппингом, и кучей вложенных if() и т.д. Но все-таки и тут можно применить с функцией интерпретации date#(), при условии, что все наименования месяцев написаны одинаково, и подчиняются одному формату (а не январь 2021 и янв. 21 в другой строке).
В секции Main посмотрите, какие значения прописаны в переменной LongMonthNames. Если это русские месяцы, которые начинаются с «Январь», то все ок. Если не русские, то русифицируйте их, и первый месяц пусть называется «Январь».
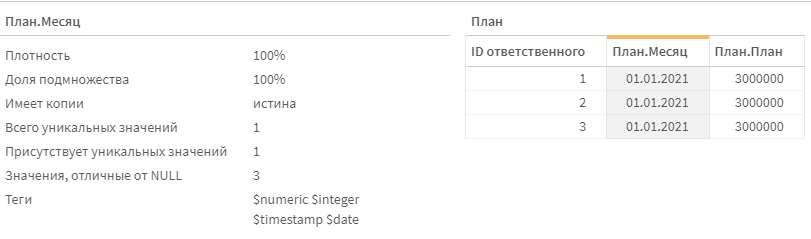
Теперь к полю Месяц в таблице План можно применить интерпретацию
date(date#(Месяц,'MMMM YYYY')) as Месяц
MMMM в маске месяца распознает полное назввание месяца. А MMM — сокращенное.
Результат:
Выводы
- Называйте поля для связи однообразно, с отличительным набором символов вроде ID. Это упростит вам квалификацию имен полей.
- Использование функционала квалификации имен полей гарантирует, что ваша модель не сломается при добавлении очередного поля в таблицу с данными.
- Обязательно контролируйте, что поля, которые будут формировать единую временную ось, имеют тег $date.
- Заменяйте значения недействиетльных дат на null(), для оптимизации и улучшения пользовательского опыта работы с вашим прилоежнием.
- Если в данных указана не дата а период, пересчитайте его в первую дату периода (первый день месяца, квартала и т.д.).
- Создавайте приложения, которые загружают данные и сохраняют таблицы в причесанном виде в QVD файлы (имена полей, форматы данных и т.д.). Загружайте данные из чистовых QVD файлов в аналитические приложения, не тратя время на повторную очистку данных.