Обзор задачи
Вцелом, построение модели данных состоит из 4-х шагов:
- Подготовка таблиц;
- Построение базовой таблицы связей;
- Восстановление сковзных связей;
- Построение единой оси дат.
Для практики я подготовил вам мини-датасет. Скачивайте его. Я специально добавил в него минимум данных, чтобы вы могли видеть буквально каждую строчку в предпросмотре модели данных и понимать, как наши действия влияют на нее.
Итого, у нас есть 5 таблиц:
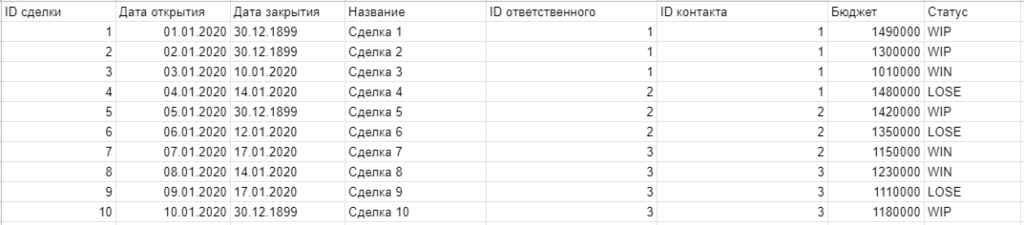


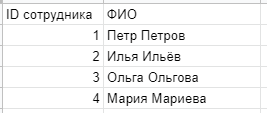

Логика дата-сета такая: сделки связаны с контактами, а контакты с компаниями. Все 3 таблицы также связаны со справочником сотрудников. Есть еще таблица с планом, где перечислены имена менеджеров, которую нажно будет сопоставлять с фактом продаж по успешным сделкам.
Таблица сделок имеет 2 даты — открытия и закрытия. Нужно сделать модель, в которой мы сможем анализировать на одной временной оси события по созданию и закрытию сделок, а также сопоставлять факт продаж с планом.
Загрузка данных через скрипт
Создайте новое приложение, и на экране выбора способа загрузки данных выберите редактор скриптов.
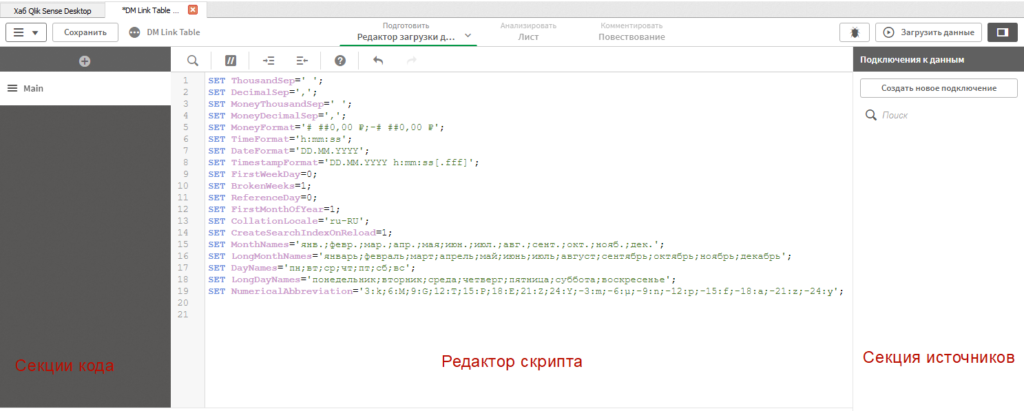
Редактор скрипта состоит из 3-х блоков:
- Секции кода — тут можно разбивать свой скрипт на блоки, чтобы не писать простыню на 100 экранов. Блоки всегда кода выполняются последовательно.
- Редактор скрипта — сюда мы будем писать наш код для формирования моделей данных. В новом приложении, тут изначально присываются системные переменные, большая часть из которых относится к представлению формата чисел и дат в приложении.
- Секция источников — тут содержатся преднастроенные подключения к источникам (файлы, БД и т.д.), из которых мы можем загружать данные.
Создайте новую секцию скрипта, назвав ее Данные.
В правом верхнем углу щелкните по кнопке «Создать подключение». Выберите вариант Папка, и пропишите путь до файла, который вы скачали в начале занятия.

Дайте любое название этому подлючению, и нажмите кнопку «Создать». Учтите, что вы подключаетесь не к конкретному файлу, а к папке. Поэтому файлы на этом этапе будут некликабельны.
У созданного источника щелкните по кнопке «Выбрать данные»
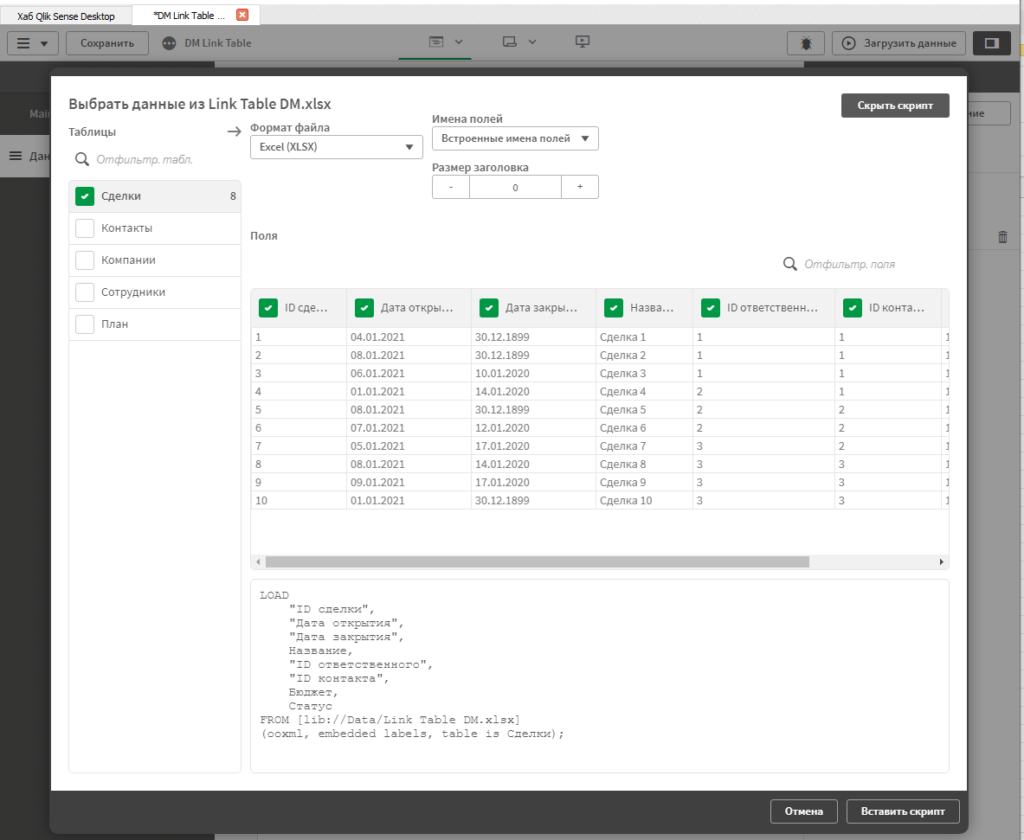
Откройте наш файл с данными. Вы увидите режим предпросмотра данных в источнике. Галочками можно отмечать таблицы и поля, котоыре вы хотите загрузить. Пока, ограничимся только таблицей сделки. Нажмите кнопку «Вставить в скрипт» справа внизу, чтобы добавить в скрипт загрузку данных из этой таблицы.
Так выглядит стандартный код загрузки данных из источника.

Перед оператором LOAD можно прописать название таблицы, которое мы хотим получить в нашей модели данных. Если этого не сделать, то Qlik возьмет название из источника, или сгенерирует его сам. Лучше прописывать название таблиц в явном виде, т.к. в будущем нам этом пригодится.
После оператора Load перечисляются поля, которые мы получаем из источника. Можно писать как оригинальные поля источника, так и производные, типа [Сумма продажи]-[Маржа] as [Себестоимость]. Внутри оператора Load можно ссылаться только на поля, которые присутствуют в источнике. Т.е. формул на основе полей из разных таблиц прописать нельзя. Только если предварительно совместить эти поля в одной таблице.
После перечисления полей указывается источник. Это может быть как путь к файлу, так и SQL запрос. Все зависит от формата источника. Иногда, перечисляются параметры подключения к источнику, вроде кодировки, отступов строк от начала таблицы и т.д. Эти параметры настраиваются через отбор данных в правой секции, нет смысла их заучивать.
Нажмите кнопку «Загрузить данные» справа вверху, чтобы данные из источника попали в приложение Qlik Sense.
Приложения Qlik хранят в себе все данные, полученные на момент последнего выполнения скрипта.
После загрузки данных, в верхнем меню, в разделе «Подготовить», выберите «Просмотр модели данных».
Здесь вы увидите предпросмотр загруженных таблиц и связей между ними. Посмотреть содержимое таблицы можно, открыв панель предварительного просмотра.
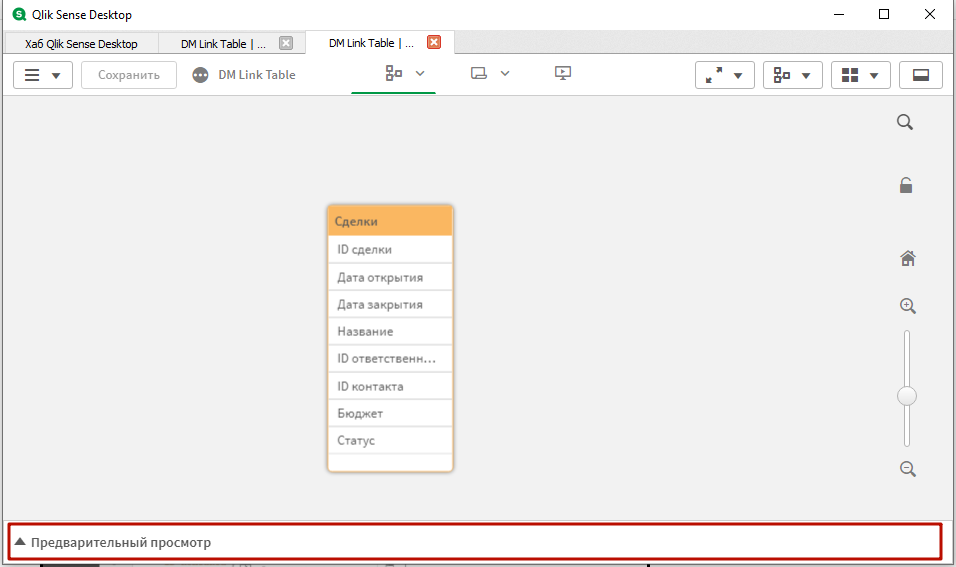
Здесь можно посмотреть первые 50 записей в таблице, и что более важно, различные параметры полей. Выберите поле «Дата открытия». Разберем параметры на его примере.
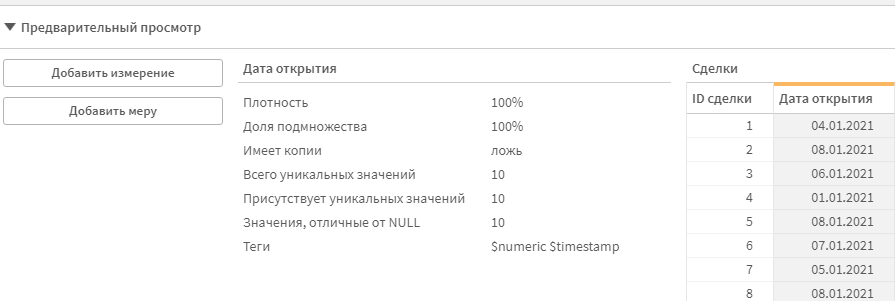
- Плотность — % непустых значений. Под пустыми значениями имеется в виду Null. Т.е. именно отсутствуюзие значения, а не, например пустота типа «».
- Доля подмножества — какой % значений поля присутствует именно в этой таблице. Поля с одинаковым названием в разных таблицах (ключевые поля) в Qlik собираются в одно поле, содержащее все значения этого поля из всех таблиц.
- Имеет копии — есть ли дубликаты значений, или же все они уникальные.
- Всего уникальных значений — сколько уникальных значений у этого поля во всех таблицах.
- Присутствует уникальных значений — сколько уникальных значений этого поля есть конкретно в этой таблице.
- Значения, отличные от NULL — кол-во непустых значений.
- Теги — тип данных, который Qlik Распознал в поле, при условии, что это единственный тип данных в этом поле.
Вообще, у полей в клике нет такого свойства, как хранимый тип данных. Т.е. мы не объявляем что это поле 1 содержит целые числа, поле 2 текст, а поле 3 дробные числа.
Но если все записи в поле относятся к одному типу, клик отметит такое поле соответствующим тегом, например $numeric для числовых полей. Если в поле содержится несколько типов данных, например числа и текст, то тег присвоен не будет.
Наличие тега у поля никак не ограничивает нас в догрузке в него данных другого типа.
Вернитесь в скрипт загрузки, и добавьте код загрузки из остальных таблиц. Обязательно пропишите им названия в явном виде.
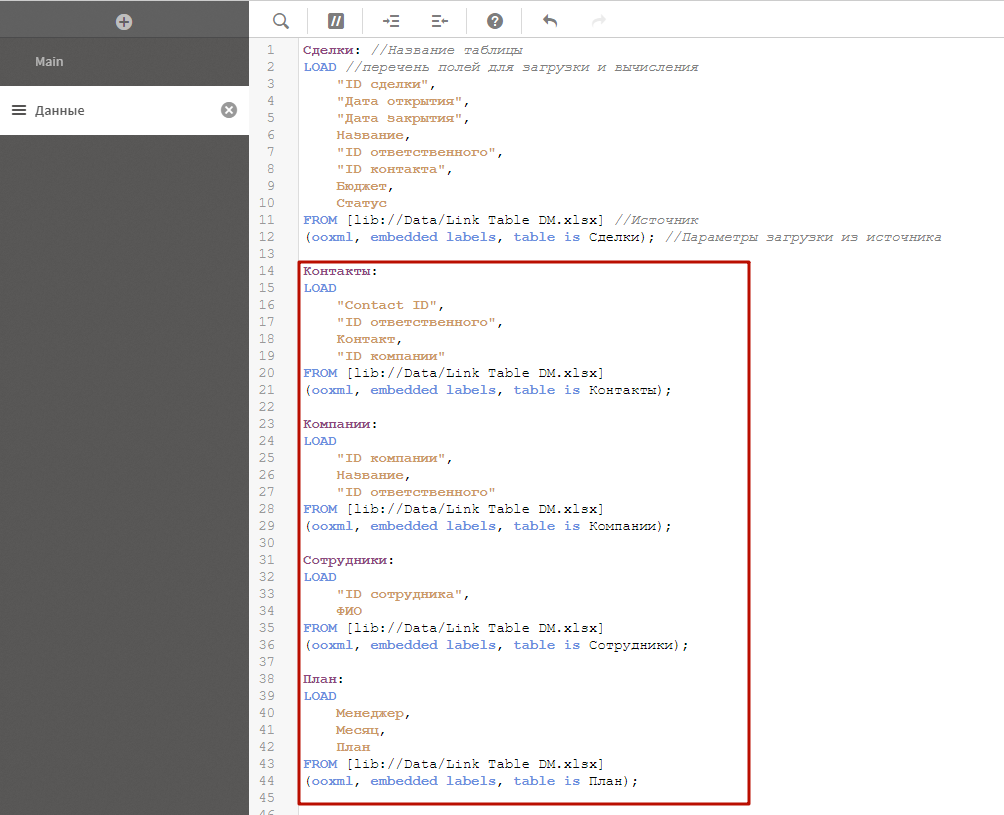
Загрузите данные. В этот раз, по завершению загрузки вы получите предупреждение, что данные загружены, но были созданы синтетические ключи.
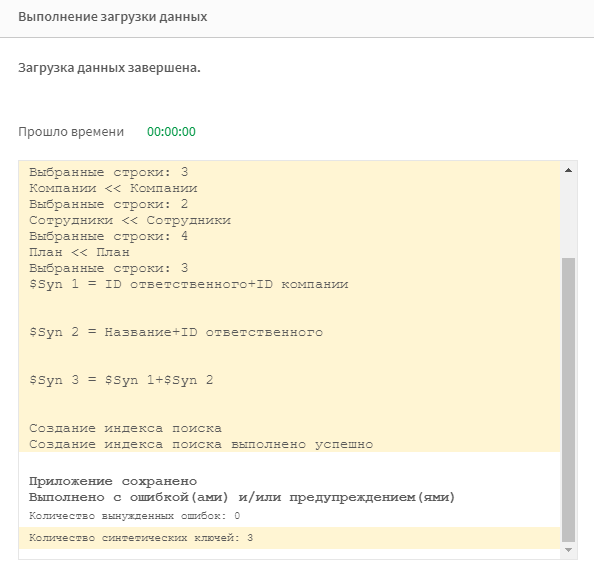
Что это за ключи? Давайте разбираться.
Синтетические ключи в Qlik
Посмотрим в модель данных. Выглядит она немного странно. Таблицы Сотрудники и План парят в вакууме. Остальные таблицы сязаны через синтетические ключи.
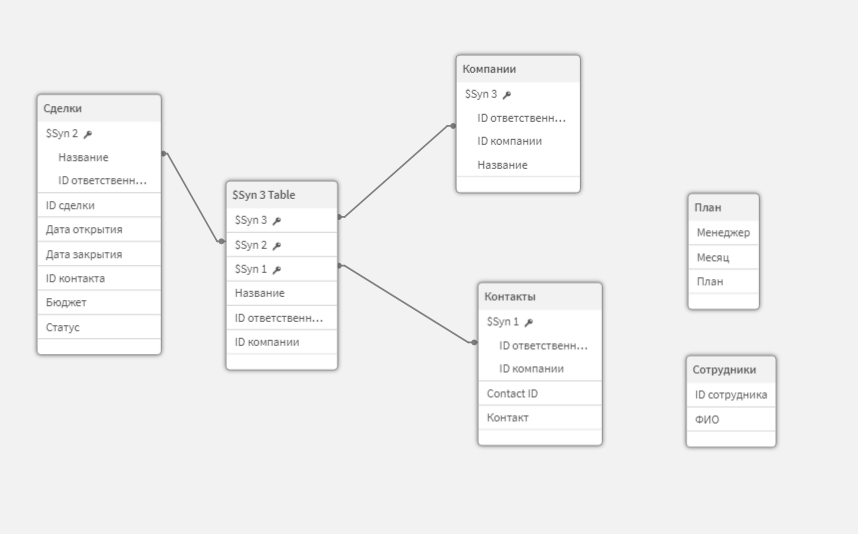
Т.к. в клике нет понятий первичный-вторичный ключ, связи между таблицами происходят автоматически, на основе полей с одинаковыми названиями.
Если таблицы связаны не по одному полю, а по нескольким, то между ними образуется синтетический ключ. Т.е. доп. таблица, которая содержит все комбинации значений общих полей из обеих таблиц.
Синтетические ключи также могут являться частью других синтетических ключей, что конечно уже ни в какие ворота не лезет. Хотя само наличие синтетического ключа не говорит о том что в модели что-то неправильно, их присутствие создает больше проблем чем пользы. Потому что:
- Синтетический ключ может сроиться по полям, по которым связи быть не должно. Например, как у нас по полю «Название».
- Синтетические ключи работают медленнее, чем составные ключи на основе того же самого набора полей. Заметно станет на объемах данных под несоклько миллионов строк.
- Синтетические ключи формируют непредсказуемые, сложнопонимаемые связи.
Поэтому правилом хорошего тона считается полное отсутствие таких ключей в модели. Чтобы этого добиться, мы должны взять формирование связей в свои руки.
Что касается оторванных от модели таблиц, думаю вы уже догадались — в них просто нет полей с общими названиями в других таблицах.
Заключение
- Клик помогает сгенерировать код для запроса данных к источнику;
- Таблицам нужно задавать явные названия;
- Синтетические ключи — это плохо, им нельзя доверять.