Когда данные очищены, и с именами полей полный порядок, можно взяться за создание таблицы связей. Создайте секцию скрипта после Данных, назвав ее Link Table TMP.
Каркас таблицы связей строится в 3 этапа:
- Получение полей связи из всех таблиц во временные таблицы связей;
- Склеивание временных таблиц связей в одну таблицу связей;
- Удаление избыточных полей связи из исходных таблиц.
Создание временных таблиц связи
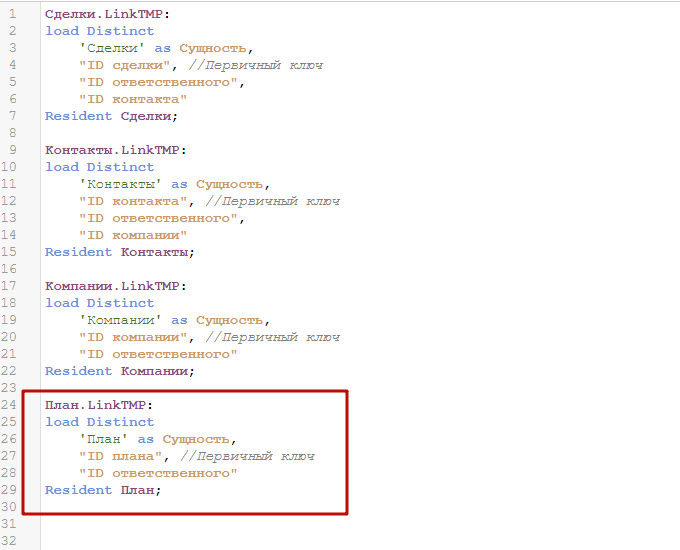
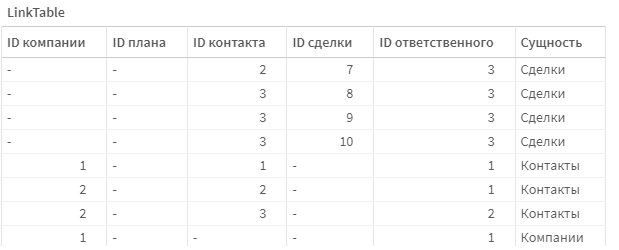
Смысл временных таблиц связи в том, чтобы запросить из каждой таблицы все поля связи с другими таблицами, а также первичный ключ самой таблицы. Дополнительно, мы создадим служебное поле «Сущность», в которое пишем название оригинальной таблицы с данными. Оно поможет нам правильно агрегировать данные в визуальном слое, например по ответственным. Которые представлены в сущеностях Сделки, Контакты и Компании.

Слово Distinct после Load говорит о том, что в результирующей таблице будут только уникальные строки, т.к. для таблицы связей не нужны избыточные записи. Т.к. мы грузим данные из ранее загруженной в модель таблицы, в качестве источника у нас идет Resident Сделки.
Повторяем процедуру для таблиц Контакты и Компании.

С таблицей План опять затык. Дело в том, что в ней нет первичного ключа. Только поле ID отсветственного. А нам нужен первичный ключ, для того чтобы связывать таблицу с данными и итоговую таблицу связей. В этом случае можно идти двумя путями.
- Ленивый путь. Создать в таблице поле счетчика строк через функцию rowno(), и использовать его как первичный ключ.
- Оптимизационный путь. Создать в таблице составной ключ, на основе комбинации всех полей связи и полей дат, которые пойдут в единый календарь.
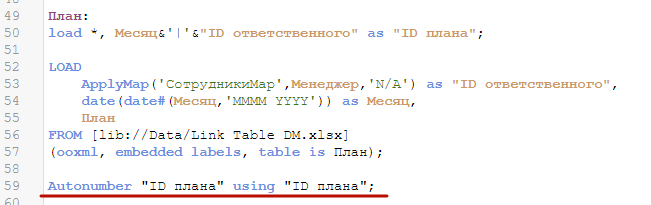
Пойдем по оптимальному пути. Вернемся к загрузке данных плана, и пропишем туда такую строку:

В чем фишка: если прописать Load без указания источника данных, то будет образовывать сложенный запрос со следующим Load’ом. Это называется Preceding Load. Его удобно использовать для создания полей на основе вычисленных полей, которых нет в источнике.
Т.е. мы не могли внутри одного Load склеить поля Месяц и ID ответственного, потому что их нет в источнике. Пришлось бы склеивать сами формулы, а это усложнило бы наш синтаксис.
Так, верхний Load содержит знак *, который загружает все поля из предыдущего Load, и создает новое состовное поле «ID плана».
В составных полях обязательно склеивайте значение через разделитель. Потому что значения полей вроде 1 и 11, а также 11 и 1 дадут без разедлителя результат 111, что нарушит логику связей.
После загрузки плана пропишите вот такую строку. Она преобразует все значения составного ключа в числа. Любые операции над числовыми значениями в Qlik выполняются быстрее, чем над текстовыми.
В чем профит использования составного ключа вместо rowno()? Дело в том, что уникальных вариантов составного ключа может оказаться меньше, чем строк в таблице с данными. А значит наша таблица связей получится менее избыточной, что положительно скажется на ее быстродействии и потреблении прилоежнием памяти.
Теперь мы можем дописать формирование временной таблицы связи для плана.
Справочники обычно не добавляют в таблицу связей, т.к. они просто коннектятся по единственному ID к готовой таблице связей. Поэтому Сотрудников мы не добавляем.
Сбор центральной таблицы связей
Создайте новую вкладку, назвав ее Link Table
На предыдущем шаге мы создали множество отдельных кусочков таблицы связей, с теперь склеим их в одну центральную таблицу. Вы можете спросить — «А что, нельзя было сразу склеить?». Нет, нельзя. Почему, узнаете дальше.
Начнем с вот такой записи:

Этот фрагмент кода загружает все данные из таблицы Сделки.LinkTMP, а потом удаляет ее. Зачем нужен NoConcatenate? Дело в том, что если мы загружаем любым способов таблицу, в которой набор полей совпадает с уже существующей таблицей, то Qlik автоматом их склеивает в одну (Сделки.LinkTMP в данном случае). А нам нужно чтобы создалась именно новая таблица, в которую потом добавятся данные из других таблиц. Поэтому NoConcatenate перед Load отключает автосклеивание совпадающих таблиц.

А вот данные из последующих таблиц наоборот надо грузить с указанием команды concatenate, чтобы их строки пристраивались в уже существующую таблицу LinkTable.
На этом в общемто и все. Не забывайте удалить временные таблицы связи.
Удаление полей связи из исходных таблиц
Теперь мы просто удаляем все поля связей, которые не являются первичными ключами в этих таблицах. Для каждой таблицы перечисляем свой список полей.
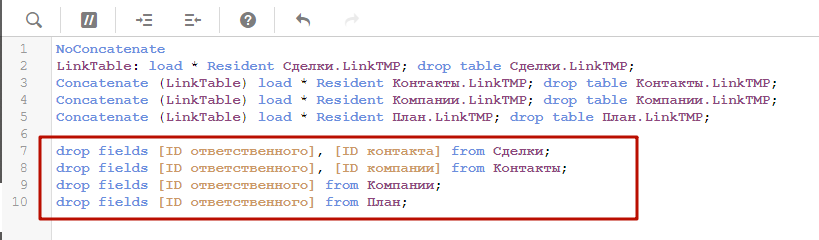
Загрузите данные. Теперь наша модель работает без синтетических ключей
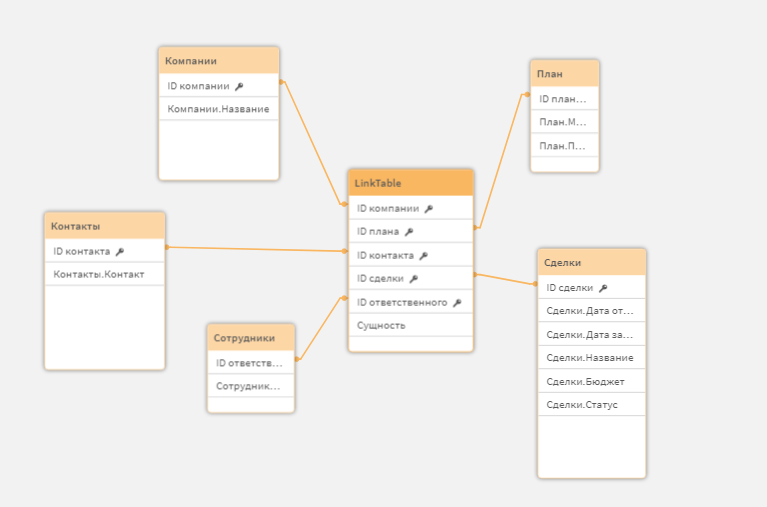
Таблица связей содержит все общие поля, а соединение таблицы связей и таблицы с данными проходит по первичным ключам.
Но не даром эта тема называется «Каркас таблицы связей». Осталась еще пара моментов, которые мы разберем в следующих темах.
Добрый день! В каких случаях необходимо создавать таблицу с NoConcatenate?
Здравствуйте. Если в скрипте загружается таблица, набор полей в которой полностью совпадает с полями уже существующей в модели таблицы, то они соединятся в одну таблицу. Чтобы этого не произошло, перед load нужно писать noconcatenate.
Евгений, добрый день!
Подскажите, пожалуйста, как поступать, если одна таблица ссылается на другую дважды? Предусматривает ли ваш алгоритм такую ситуацию?
Например, две таблицы: Заявки и Пользователи. Но в таблице Заявки есть два поля, ссылающихся на Пользователей: Автор и Исполнитель. Как в этом случае строить таблицу связей? Можно ли обойтись без дублирования таблицы Пользователей?
Да, лучше сделать отдельные справочники. Альтернатива — задваивать связь в таблице связи (на каждую запись в фактах будет 2 записи в таблице связи, одна где ид пользователя автор, вторая где ид пользователя исполнитель. Значения из 2-х полей сводятся в одно поле). Но это минимум в 2 раза увеличит записи в таблице связи, а также вынудит вас писать в анализе множеств доп. условия, по какому типу пользователя проводить агрегацию. Или выводить доп. фильтры в приложении. Исходя из практики, могу сказать что первый вариант лучше.