В предыдущих материалах мы рассказывали, как создать каталог всех доступных для анализа данных с помощью базового функционала Qlik Sense. Иметь перечень таблиц и полей в виде понятного списка очень удобно. А было бы еще удобнее, если бы можно было оперативно получать представление, что за данные в этих полях находятся.
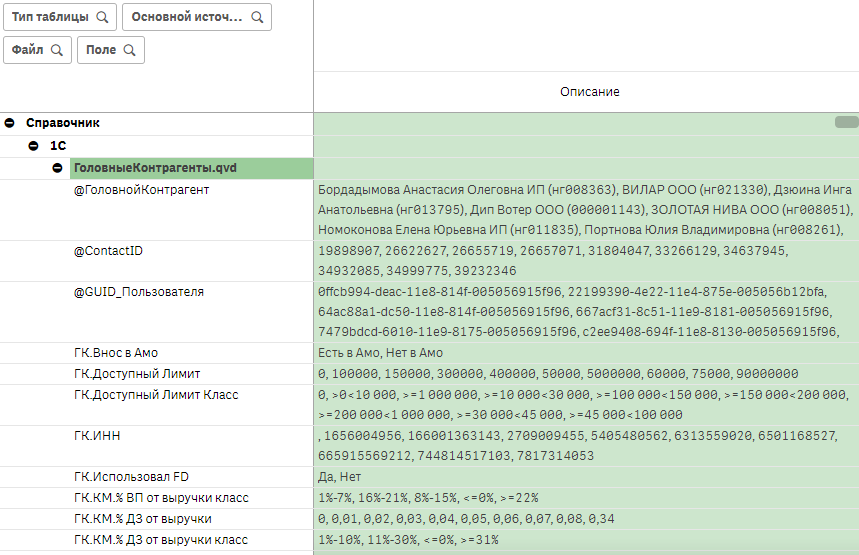
Аудит данных может потребоваться на многих уровнях — посмотреть, как работают ассоциации между таблицами, посмотреть содержимое строк таблицы. Но очень часто достаточно именно просмотра значений конкретного поля.
Для этого нам была бы нужна примерно такая модель: таблица с перечнем таблиц и полей, и таблица со значениями полей каждой таблицы. Поговорим о том, как такую таблицу получить.
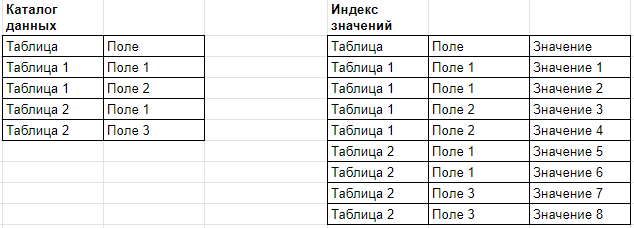
Генерация индексной таблицы
Знали ли вы, что можно получить список значений поля таблицы, загруженной в модель Qlik Sense, непосредственно из индексной таблицы движка, не прогружая все поле целиком через load distinct? Т.е. если у вас загружена таблица на 100 млн строк, и в ней есть поле Магазин, в котором 1000 уникальных значений, то можно получить именно эту тысячу значений, не прогружая все 100 млн строк.
Делается это следующей конструкцией
FieldValues: load
FieldValue('FieldName',recno()) as FieldName_Values
autogenerate FieldValueCount('FieldName');Таким нехитрым способом вы сгенерируете поле, содержащее все уникальные значения поля FieldName. Учитывайте, что в него попадут значения из всех таблиц, т.к. на уровне модели поля с одинаковыми именами в разных таблицах объединяются в одно поле.
Конечно, нам для нашей задачи потребуется чуть больше чем просто список значений полей. Мы пока остановились на таком наборе:
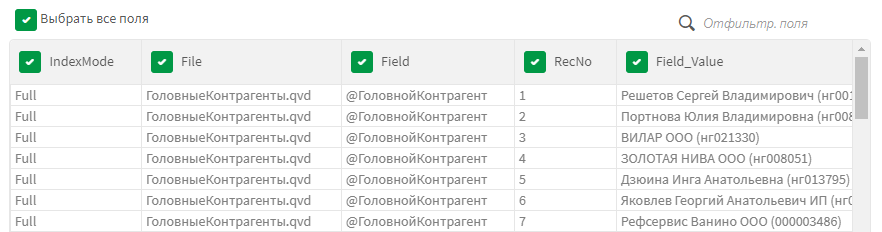
- IndexMode — режим индексации значений, полный или ограниченный;
- File — название QVD файла или другой таблицы, с которым ассоциируется индекс;
- Field — поле, которое индексируется;
- RecNo — порядковый номер значения;
- Field_Value — значение поля;
Чтобы удобно генерировать такой массив, можно использовать подпрограмму:
sub IndexGenerate(Table,File,UniqueLimit,FieldLimit,StorePath)
For f = 1 to NoOfFields('$(Table)')
IndexFields:
Load
FieldName($(f),'$(Table)') as IndexFields
Autogenerate 1;
Next f
For Each vIndexFields in FieldValueList('IndexFields')
if FieldValueCount('$(vIndexFields)')>UniqueLimit then
set vLoadLimit=first $(FieldLimit);
set vIndexMode=Preview;
else
set vLoadLimit=;
set vIndexMode=Full;
End If
[$(Table)_index]: $(vLoadLimit)
load
'$(vIndexMode)' as IndexMode,
'$(File)' as File,
'$(vIndexFields)' as Field,
RecNo() as RecNo,
FieldValue('$(vIndexFields)',RecNo()) as Field_Value
AutoGenerate FieldValueCount('$(vIndexFields)');
next
store [$(Table)_index] into [$(StorePath)/$(Table)_index.qvd] (qvd);
drop table [$(Table)_index];
drop table IndexFields;
end subРазместите ее в скрипте до загрузки данных.
Вызов подпрограммы происходит так:
call IndexGenerate('Отгрузки','Отгрузки.qvd',100000,10,'lib://QVD Layer 2.0/QVD Index')
//Имя таблицы в модели, название источника индекса, лимит уникальных значений, кол-во если лимит превышен, путь сохранения индексаРазберем ее параметры:
- Название таблицы в модели, для которой строится индекс. Не забывайте, что не смотря на этот параметр, индекс будет построен по всем значениям поля во всех таблицах. Поэтому индекс лучше строить когда в модели одна таблица или вы точно уверены, что ее поля не пересекаются с другими таблицами.
- Название источника индекса. Вспомогательное значение, которое будет записано в индекс, для построения связей с каталогом.
- Лимит уникальных значений поля. Если в поле уникальных значений больше чем в указанное число, то будет загружено кол-во значений, не превышающее следующий аргумент. Если число значений не больше лимита, то поле IndexMode определяется как Full, иначе как Preview;
- Кол-во значений поля, которое отбирается, если был превышен лимит из предыдущего аргумента. Если в поле содержится 1 млрд уникальных чисел, возможно это не очень актуально для предпросмотра;
- Путь сохранения индекса.
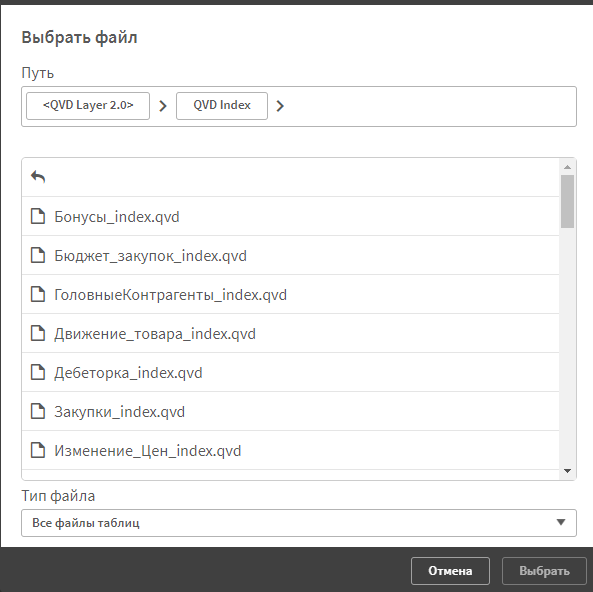
Вот вам бонусом код, который построит индекс по всем qvd файлам в папке и сохранит в отдельные файлы
For each vFile in FileList('lib://QVD Layer 2.0/Analytical/*.qvd')
let vFileName=SubField('$(vFile)','/',-1);
let vTableName=subfield(SubField('$(vFile)','/',-1),'.',1);
trace $(vTableName)/$(vFileName);
[$(vTableName)]:
LOAD
*
FROM [$(vFile)]
(qvd);
call IndexGenerate('$(vTableName)','$(vFileName)',100000,10,'lib://QVD Layer 2.0/QVD Index')
//Имя таблицы в модели, название источника индекса, лимит уникальных значений, кол-во если лимит превышен
drop Table [$(vTableName)];
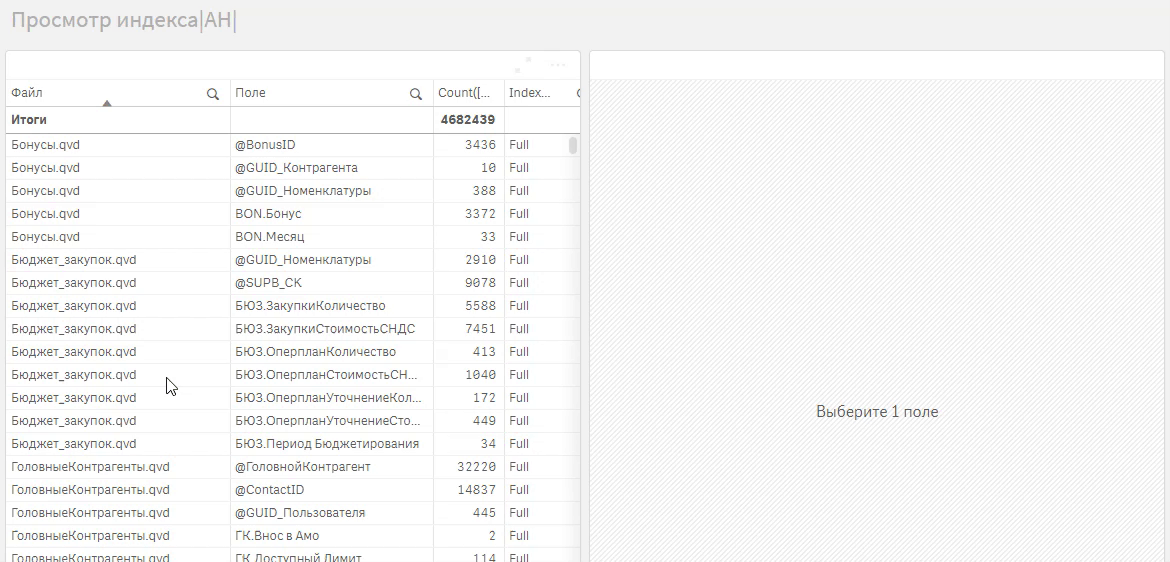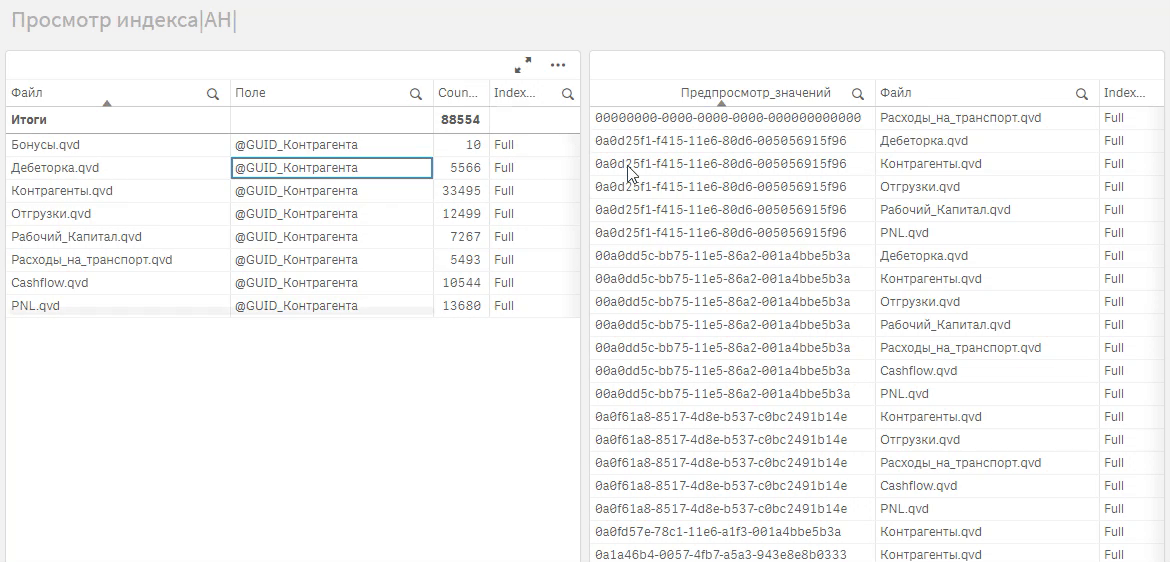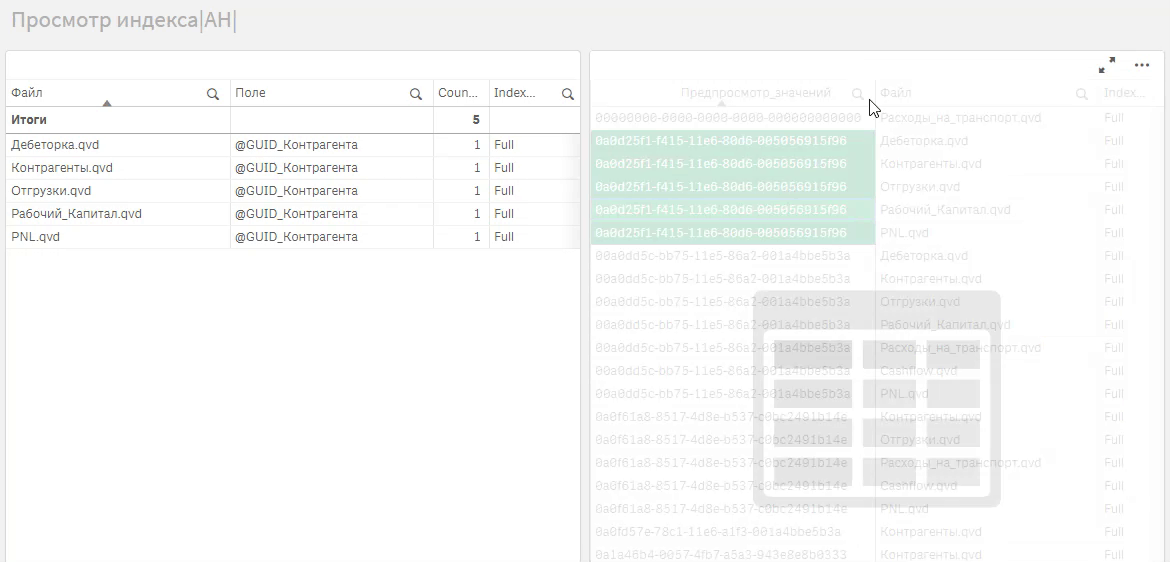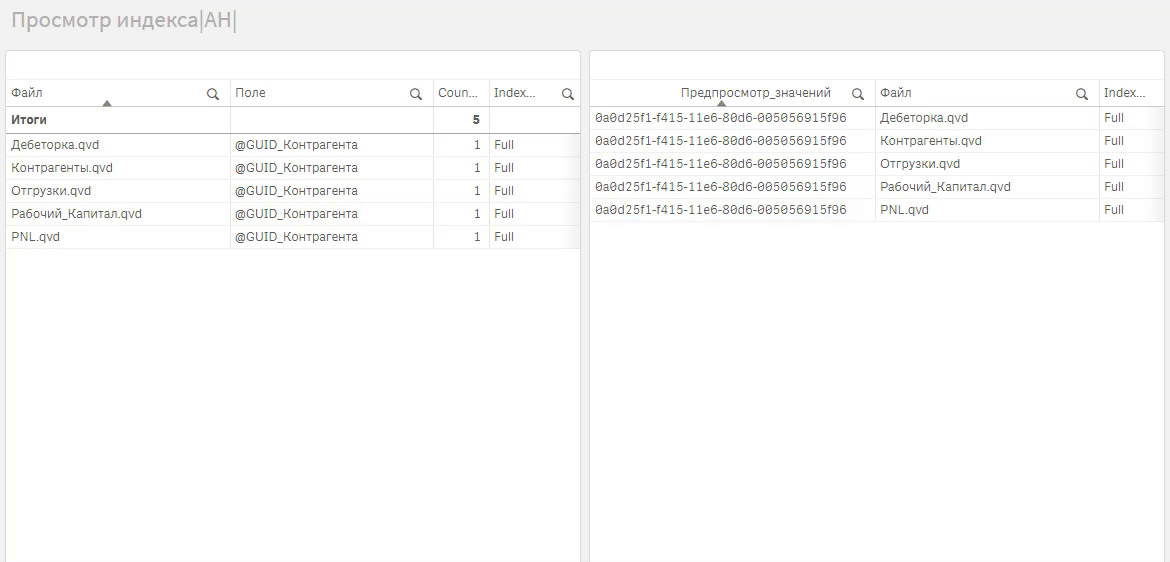
nextРезультат:
Теперь, можно в каталоге приложений использовать формулу вида:
Concat(distinct {<RecNo={"<=10"}>} [Field_Value],', ')Если использовать ее в сводной таблице с измерениями Таблица и Поле, то получите предпросмотр данных:
Также полученный индекс удобно использовать для поиска, где в данных встречается то или иное значение.
Задавайте вопросы и делитесь впечатлениями в комментариях 🙂