Есть в Qlik Sense такая классная функция — class(). Она позволяет преобразовать значения поля в интервалы с фиксированным шагом.
Выглядит ее работа примерно так:
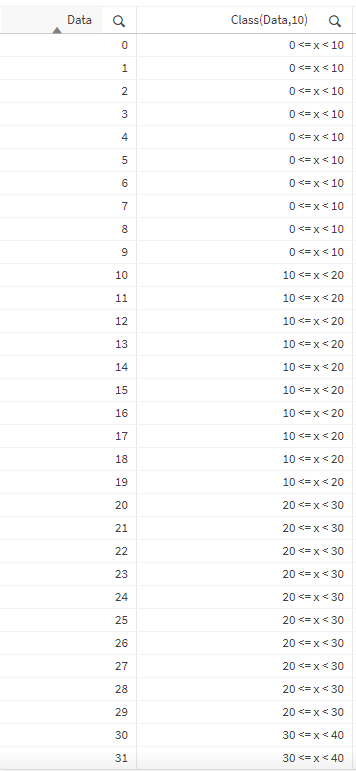
Проблема в том, что в базовом функционале class() разбивает данные на одинаковые интервалы. А если у нас в классифицируемом поле большой разброс значений, то нам могут понадобиться разные условия группировки в зависимости от значения числа. Например, бить на группы по 10 значений числа от 0 до 100 это ок. Но начиная со 100 до 1000, возможно целесообразно разбивать их на группы по 100 значений. Или по 250. Для этого обычно надо писать функцию со вложенными if(), прописывая там условие что если число <100, то class(число, 10) и т.д.
Так как я очень это делать не люблю, то потратил вечер на придумывание конструкции, которая сама бы писала этот вложенный if(), на основе простого ввода условий. Для этого надо в визуальном слое создать переменную, например vClass, и вставить в нее следующий код:
$(=
'if($1<'&SubField('$2','|',1)&',dual('&chr(39)&'<'&SubField('$2','|',1)&chr(39)&','&SubField('$2','|',1)&'-1),'&
'if($1>='&subfield(SubField('$2','~',-2),'|',2)&',dual('&chr(39)&'>='&subfield(SubField('$2','~',-2),'|',2)&
chr(39)&','&subfield(SubField('$2','~',-2),'|',2)&''&
left(mid(replace(
replace('
$(=
mid('$2',len(subfield('$2','|',1))+1)
)',
'~',',class($1,'
),'|','),if($1<')
,1),
len(
mid(replace(
replace('
$(=$()
mid('$2',len(subfield('$2','|',1))+1)
)',
'~',',class($1,'
),'|','),if($1<')
,1)
)+1
)&Repeat(')',SubStringCount('$2','|')+3)
)Обязательно следите, чтобы перед первым $ у вас не было знака «=»!
Теперь вы можете обращаться к этой переменной, используя 2 аргумента:
- Название поля или выражение, которое вы хотите классифицировать;
- Порядок классификации.
$(vClass(Data,50|100~10|1000~100|10000~1000|50000~2500|100000~10000))Первое число — начало классификации. Все что меньше его, будет отмечено как <50. Далее, через вертикальную черту пишем пары значений. Первое значение — это уровень, до которого будет работать классификация. Второе значение — детализация разбивки групп. Пар значений может быть сколько угодно. В примере написано буквально следующее:
«Разбей значения на группы: Те, что <50, от >=50 до <100 на группы по 10, от >=100 до <1000 на группы по 100, от >=1000 до <10000 на группы по 1000, от >=10000 до <50000 на группы по 2500, от >=50000 до <100000 на группы по 10000, и на группу >=100000».

Все что меньше первого числа (50) и больше или равно последней явно заданной границе диапазона (100000) будет объединено в 2 соответствующие группы. Промежуточные значения будут разбиты на диапазоны в соответствии с настройками классификации.