Хотя Qlik Sense позволяет решать задачи аналитики разными способами, есть ряд рекомендованных подходов для обеспечения наилучшей производительности ваших приложений. Неприменение этих подходов не сделает вашу аналитику нерабочей, но может привести к проблемам при масштабировании, связанным с ростом кол-ва пользователей и объема данных, а также сложности моделей.
Рекомендации по росту производительности затрагивают 3 уровня:
- Скорость загрузки данных;
- Ресурсоемкость приложений (объем потребления оператиной памяти);
- Скорость работы визуального слоя приложений.
Начнем же.
ETL (подготовка данных)
QVD-слой. Создайте приложения подготовки данных, которые загружают данные из источников, очищают их, и сохраняют в QVD-файлы для дальнейшего использования аналитическими приложениями. Ваши скрипты станут проще, а преобразование данных не будет происходить повторно — вы сразу будете брать готовые данные.
Используйте инкрементальное обновление данных. Не перезагружайте данные из источника полностью, берите только измененные/новые данные. Остальное подтягивайте из QVD-файлов. Справка
Создайте агрегированные QVD-файлы. Не обязательно сразу давать пользователю аналитику на исходных данных. Если исходные таблицы очень большие (миллионы записей), стоит сделать их агрегированные варианты. Вместо реестра отгрузок — суммы отгрузок в разрезе Месяца, Клиента, Товара, Магазина. Кол-во строк данных сильно сократится, приложение будет работать быстрее и потреблять меньше ресурсов. При необходимости, доступ к базовыми данным можно дать с помощью функционала ODAG или Dynamic Views.
Уменьшайте уникальность данных. Чем меньше в поле уникальных записей, тем меньше ресурсов будет пореблять его обработка и визуализации. Если в исходной базе есть поле Timestamp (Дата+время), потенциально оно содержит очень много уникальных значений. Его можно разбить на 2 поля: Дата — не более 366 уникальных значений за год, и Время. Поле Время нужно округлить до необходимого уровня детализации. Если аналитика глубже часа не нужна — округляем до часа.
Упрощайте данные. Операции над числами выполняются быстрее чем операции над текстом. Более короткие значения потребляют меньше памяти. Если в ваших данных есть поля вроде GUID документа со значениями типа 0a0d25f-f415-11e5-64adfbbb-6645c, спросите себя: “реально ли для аналитики необходимо наличие именно таких значений в этом поле”? Если нет, то можно обработать поле функцией autonumber вне оператора load.
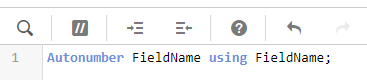
Это преобразует все уникальные значения поля в последовательные числа. Связь элементов по полю сохранится, но значения будут потреблять меньше памяти. Если нужно сохранить уникальность номера независимо от порядка загрузки — используйте функцию hash. На выходе будут конечно не числа, но уже более короткие значения чем GUID. Конечно, нужно исопльзовать это только если вам не требуется использовать оригинальные значения в аналитических целях.
Создавайте флаги для подсчетов. Суммирование (sum) работает быстрее чем подсчет (count). Заметно на больших объемах данных. Вместо подсчета уникальных элементов (count (distinct Deal_ID)) можно создать в таблице поле со значением 1, и выполнять суммирование по нему (sum(DealCountFlag))
Попробуйте перенести часть обработки данных на запрос к БД. Особенно если это касается агрегирования или сложного объединения таблиц. Однако помните, что тогда на БД будет повышенная нагрузка. Лучше комбинировать этот подход с инкрементальной загрузкой.
Excel — самый медленный формат для загрузки данных. Если есть необходимость грузить большие объемы данных из таблиц, пусть они будут в CSV.
Используйте подход preceding load для последовательного преобразования таблиц где это возможно, вместо resident. Это позволит вам ссылаться на имена рассчетных полей, не инициируя перезагрузку данных из таблицы. Кроме того, читабельность вашего кода возрастет.
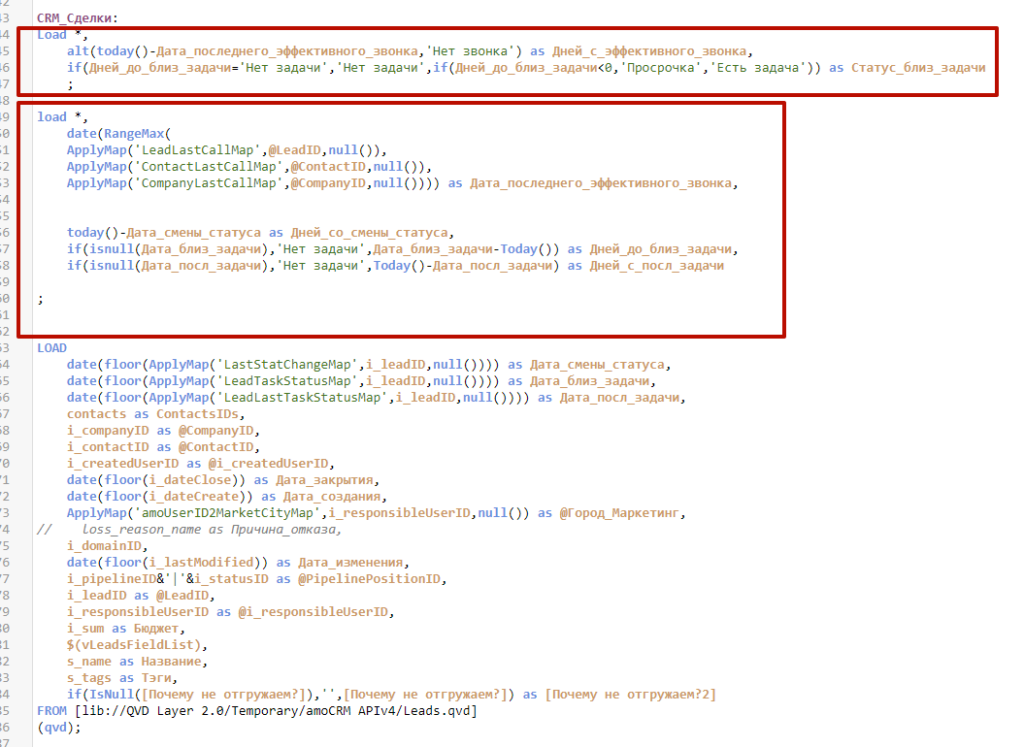
Скрипт и построение модели
Стремитесь свести модели данных к топологии Звезда (все таблицы объединены через центральную таблицу связей). Чем меньше в модели переходов между таблицами, тем быстрее работает отрисовка визуализаций.
На больших объемах данных, выносите в центральную таблицу связей также поля, по которым считаются меры. Когда переходов между таблицами нет, вычисления работают еще быстрее.
Учитывайте, что нету единой правльной топологии, т.к. существуют сценарии связи данных, которые нельзя реализовать в конкатенированных фактах, т.к. это приведет к дублированию данных (например, связи один-ко-многим).
Удаляйте временные таблицы как только они стали не нужны, а не тяните их до конца скрипта для массового уничтожения.
Используйте команду Search, чтобы в явном виде обозначить поля, для которых нужно делать индексацию интеллектуального поиска (вместо полного включения/выключения).
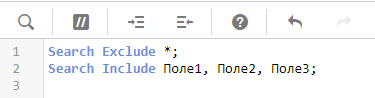
Не используйте DERIVED-поля на больших объемах данных. Т.к. эти поля на самом деле считаются на лету в визуальном слое (сюрприз).
Не ломайте Оптимизированную загрузку QVD-файлов. Иначе говоря — загружайте их без изменений, а ограничения по загрузке данных прописывайте только через where exist. Нужно внести изменения в данные QVD-файла — делайте это в приложении которое его формирует.
Обновляйте приложения через бинарную загрузку. У вас несколько одинаковых приложений (пользовательское и разработчика)? Создайте приложение с обычным скриптом, которое загружает данные. А в рабочие приложения загружайте данные из него с помощью Binary Load. И в них создавайте визуализации. Таким образом полноценная загрузка данных произойдет только один раз, а в 2 рабочих приложения данные попадут по ускоренной схеме. Что в итоге быстрее, чем обновлять 2 приложения через полную перезагрузку. Таким образом загружать данные в т.ч. из папки Qlik Share на сервере.
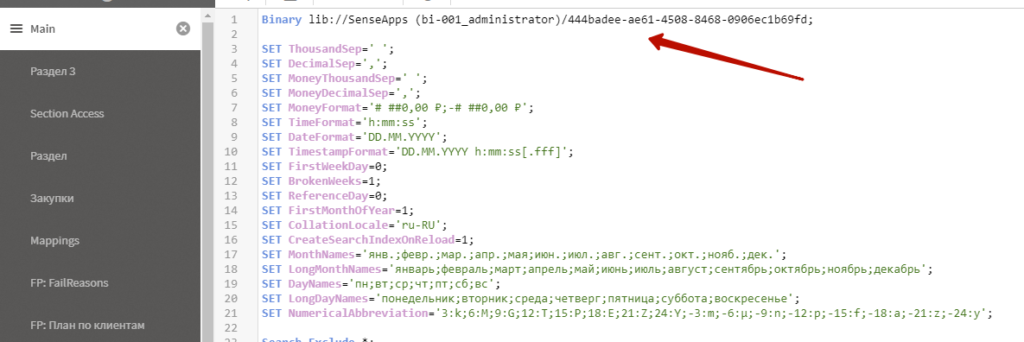
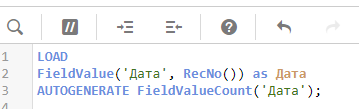
Используйте функцию FieldValue, если нужно получить список уникальных значений поля, а также минимальное или максимальное значение поля, если источник — таблица с очень большим кол-вом записей. Так вы изначально будете обращаться к только перечню уникальных значений поля, а не грузить 10 000 000 записей, а потом схлопывать до 100 уникальных. Вот такой скрипт вернет таблицу с уникальными значениями поля, и сделает это очень быстро:
Используйте составные ключи в таблицах связи вместо первичных ключей, где это возможно. Допустим, у вас есть таблица отгрузок на 10 000 000 млн. строк, с данными за 2 года. Но если для связи с другими таблицами не нужен ее первичный ключ (ИД документа), то в таблице связей можно использовать составной ключ, содержащий комбинацию общих полей с другими таблицами и дат. Таким образом, вместо 10 000 000 первичных ключей в таблицу может попасть на порядки меньше записей на основе составного ключа, например 100 000.
Удаляйте из модели поля, которые не используются в визуальном слое. Загружать ВСЕ поля прозапас — нагружать память зря.
Визуальный слой
Используйте однотипное написание формул. sum(Sales) и Sum([Sales]) вернут одинаковый результат, но каждая формула будет вычисляться заново.
Скрывайте визуализации с большим объемом данных через функцию Ограничения вычислений. Требуйте от пользователя сначала задать фильтры, а не сразу рисуйте ему таблицу на 10 000 000 строк.
Если используете функцию AGGR, подумайте, можно ли вынести эти группировки данных в скрипт загрузки.
Не злоупотребляйте вычисляемыми измерениями. Лучше выносить формирование полей, особенно по сложным условиям, в скрипт загрузки.
Создавая динамические цвета в таблицах, по возможности ссылайтесь на уже существующие в ней данные через функцию column или указание наименований мер. Это позволит использовать уже готовые вычисления вместо повторного.
Создавая динамические формулы с переменными, конструируйте формулы так, чтобы они работали без if(). Например, нам нужно чтобы формула переключалась кнопкой между кол-вом продаж и суммой продаж. Вариант с if — создать переменную vMeasure, в которой могут быть значения 1 или 2, а в формулу написать “if($(vMeasure)=1,sum(Sales),count(distinct SaleID))”. Такую формулу сложно писать и масштабировать. Вместо этого, пишите формулы прямо в переменную. А в меру подставляйте имя переменной $(vMeasure). Так можно вогнать в одну меру бесконечное кол-во вариантов, ведь вам не надо править формулу меры каждый раз — только добавлять новый вариант значения переменной.
Вместо условий if, используйте функционал Set Analysis. Условия с if проверяют построчно весь гиперкуб (массив данных, используемый для отрисовки визуализации), а Set Analysis предварительно отбирает ограниченный массив, и по нему выполняет агрегацию.
Здравствуйте!
Вопрос по бинарной загрузке. Можно ли настроить так, чтобы после бинарной загрузки данных из другого приложения, в текущем приложений данные обновлялись автоматом? Без принудительного запуска скрипта.
Только через планировщик задач