QVD файлы
Каждый раз, когда мы загружаем данные в приложение Qlik, они запрашиваются из источников в полном объеме. Если наш источник — база данных, то при каждом запуске скрипта мы отправляем в БД запрос, который будет получать все записи, например, из огромной таблицы транзакций.
А зачем нам это делать, если с прошлого обновления данных добавилось просто несколько транзакций, а остальные данные не измененились?
Наверняка вы уже знаете про то, что загружаемые в приложение таблицы можно сохранять в QVD-файлы. Из такого файла данные загружаются в приложения быстрее, чем из любого другого источника. Эти файлы используют для того, чтобы хранить в них чистовые аналитические таблицы, докрученные скриптами Qlik, которые используются в других приложениях без изменений.
Кроме того, QVD-файлы открывают нам возможность инкрементальной загрузки из источников.
Принципы инкрементальной загрузки в Qlik
Смысл инкрементальной загрузки в том, чтобы взять из источник (базы данных) только те данные, которые изменились с момента последнего обновления. Часть данных, которые не изменились, догружаются из QVD-файла и склеивается в одну таблицу. Опционально, также происходит удаление записей, которые удалены в источнике, с помощью inner join. Это все подробно описано в справке Qlik.
Мы же здесь собрались, чтобы познакомиться с инструментом, который делает процесс инкрементального обновления более удобным и управляемым.
Модуль инкрементальной загрузки
Не смотря на простоту подхода, обеспечение инкрементальной загрузки — довольно суетное дело.
- Нужно сначала создать QVD файл, а потом писать вокруг него инкрементальную загрузку;
- Нужно предусматривать сценарии для полной перезагрузки данных, если изменился набор полей в источнике;
- Нужно контроллировать содержимое переменных, содержащих отметки времени о последней загрузке;
- Возможно, вам придется разбираться с часовыми поясами, в которых фиксируются данные — если они не совпадут со временем на сервере Qlik, придется корректировать таймстампы в функции now().
Чтобы покончить с этим, и быстро запускать надежное инкрементальное обновление данных, мы разработали наш модуль в виде подпрограммы для скрипта Qlik Sense. Его код будет в конце статьи, а сейчас расскажем как он работает.
Подпрограмма покрываем самый полный сценарий инкрементальной загрузки: загрузка измененных записей с исключением удаленных в источнике записей.
Вызов подпрограммы происходит так:
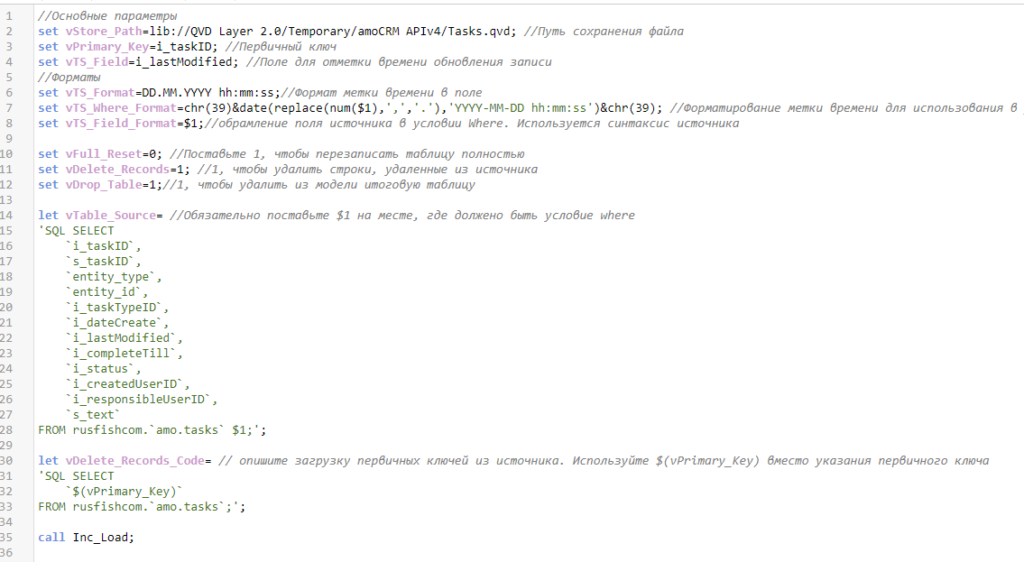
В начале идет перечисление параметров загрузки.
vStore_Path — указываем путь сохранения файла
set vStore_Path=lib://QVD Layer 2.0/Temporary/amoCRM APIv4/Tasks.qvd;vPrimary_Key — Наименование поля первичного ключа в источнике. Чтобы инкрементальная загрузка работала, в источнике обязательно должен быть первичный ключ, уникальный для каждой записи. Иначе не получится правильно догружать данные из QVD-файла.
set vPrimary_Key=i_taskID; //Первичный ключvTS_Field — наименование поля, содержащее отметку времени последнего изменения сущности. Учитывайте, что время должно быть сохранено в формате Datetime, а не Unix Timestamp.
set vTS_Field=i_lastModified; //Поле для отметки времени обновления записиvTS_Format — формат даты и времени в поле со временем изменения сущности.
set vTS_Format=DD.MM.YYYY hh:mm:ss;//Формат метки времени в полеvTS_Where_Format — форматирование метки времени для подстановки в запрос к базе данных. Метка времени обозначается как $1, вокруг нее выписываются функции форматирования.
Конструкции типа $1, $2, $3 и т.д. в переменных позволяют в будущем подставить на их место какое-либо значение при вызове переменных. Их используют для повышения универсальности кода.
Смысл в том, что в базе метка времени может храниться не в том формате, который считывает Qlik (Qlik, если распознает поле как дату, применяет к ней свой собственный формат даты). С помощью этой функции можно привести число в вид, который будет понятен базе данных в операторе where.
set vTS_Where_Format=chr(39)&date($1,'YYYY-MM-DD hh:mm:ss')&chr(39);vTS_Field_Format — обрамление поля дат в условии where. Поле определяется как $1, вокруг него пишутся функции на синтаксисе базы данных.
set vTS_Field_Format=$1;//обрамление поля источника в условии Where. Используется синтаксис источникаvFull_Reset — если установлена единица, происходит полный запрос данных из источника. Иначе говоря, отключается инкрементальное обновление. Полезно, когда в источнике изменился набор полей и нужно переписать все данные в QVD.
set vFull_Reset=0; //Поставьте 1, чтобы перезаписать таблицу полностьюvDelete_Records — задействовать ли блок кода для удаления строк.
set vDelete_Records=1; //1, чтобы удалить строки, удаленные из источникаvDrop_Table — удалять ли сформированную таблицу после сохранения в QVD.
set vDrop_Table=1;//1, чтобы удалить из модели итоговую таблицуvTable_Source — запрос к источнику. Буквально содержит код запроса, как если бы он писался непосредственно в скрипте загрузки.
Обратите внимание, что на том месте, где по логике должно располагаться условие where, по которому будут отбираться данные только с момента последнего обновления, нужно прописать $1.
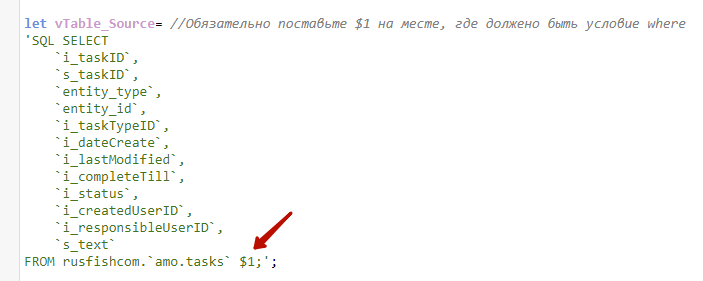
let vTable_Source= //Обязательно поставьте $1 на месте, где должено быть условие where
'SQL SELECT
`i_taskID`,
`s_taskID`,
`entity_type`,
`entity_id`,
`i_taskTypeID`,
`i_dateCreate`,
`i_lastModified`,
`i_completeTill`,
`i_status`,
`i_createdUserID`,
`i_responsibleUserID`,
`s_text`
FROM rusfishcom.`amo.tasks` $1;';vDelete_Records_Code — код для загрузки первичных ключей из БД. Нужен для дальнейшего удаления из QVD записей, несуществующих в источнике. Вместо названия поля можно написать переменную vPrimary_Key, ведь она уже содержит наименование первичного ключа.
let vDelete_Records_Code= // опишите загрузку первичных ключей из источника. Используйте $(vPrimary_Key) вместо указания первичного ключа
'SQL SELECT
`$(vPrimary_Key)`
FROM rusfishcom.`amo.tasks`;';Подпрограмма вызывается командой call Inc_Load. Никаких параметров в ней нет.
Работа подпрограммы
Если вы формируете файл первый раз, то при загрузке произойдет стандартный запрос всех данных из источника, а сами данные сохранятся в QVD файл.
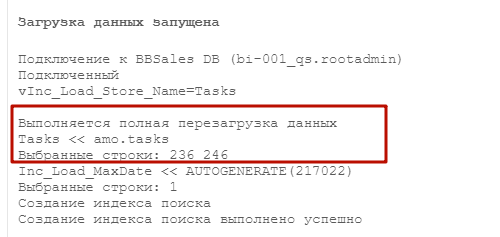
Фокус в том, что в мета-данных этого файла будет сохранена метка времени самого последнего изменения сущностей в источнике. Т.е. нам не нужно создавать переменные, которые будут помнить дату последней загрузки и как-то управлять ими. Эта информация берется непосредственно из данных.
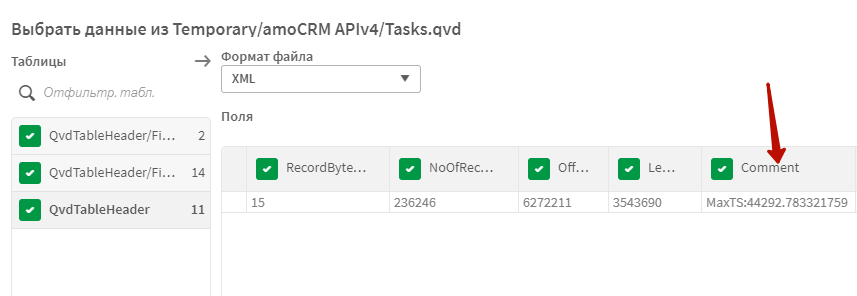
Форматирование даты в переменной vTS_Where_Format нужно для того, чтобы перевести это число в формат, который поймет база данных.
При повторной загрузке вы увидите сообщение, что выполняется загрузка обновленных данных, а также запрос к источнику с подставленным условием where. Здесь отлично видно, что число было преобразовано в дату с помощью переменной vTS_Where_Format. Переменная vTS_Field_Format позволяет нам при необходимости обработать поле с меткой времени изменения функциями на синтаксие БД.
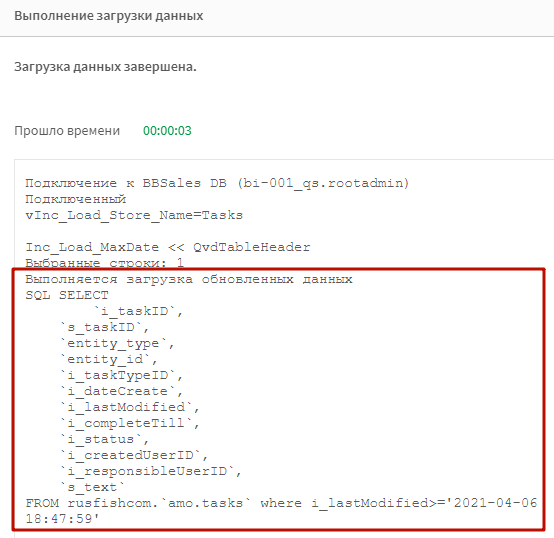
Теперь при запросе к БД будут загружаться только данные с максимальной меткой времени на последний апдейт. Остальное будет подхватываться из QVD.
Если в источнике изменится состав полей, то новые поля появятся только у записей, обновленных после добавления полей. Чтобы значения новых полей прошли у всех записей, нужно сделать полную перезапись файла с помошью переменной vFull_Reset.
Рекомендации к использованию
Используйте модуль для первичного получения данных из БД. Сложные преобразования проводите уже над QVD-файлом.
Исходный код
Пример вызова подпрограммы
//Основные параметры
set vStore_Path=lib://QVD Layer 2.0/Temporary/amoCRM APIv4/Tasks.qvd; //Путь сохранения файла
set vPrimary_Key=i_taskID; //Первичный ключ
set vTS_Field=i_lastModified; //Поле для отметки времени обновления записи
//Форматы
set vTS_Format=DD.MM.YYYY hh:mm:ss;//Формат метки времени в поле
set vTS_Where_Format=chr(39)&date($1,'YYYY-MM-DD hh:mm:ss')&chr(39); //Форматирование метки времени для использования в условии Where. Используется синтаксис Qlik
set vTS_Field_Format=$1;//обрамление поля источника в условии Where. Используется синтаксис источника
set vFull_Reset=0; //Поставьте 1, чтобы перезаписать таблицу полностью
set vDelete_Records=1; //1, чтобы удалить строки, удаленные из источника
set vDrop_Table=1;//1, чтобы удалить из модели итоговую таблицу
let vTable_Source= //Обязательно поставьте $1 на месте, где должено быть условие where
'SQL SELECT
`i_taskID`,
`s_taskID`,
`entity_type`,
`entity_id`,
`i_taskTypeID`,
`i_dateCreate`,
`i_lastModified`,
`i_completeTill`,
`i_status`,
`i_createdUserID`,
`i_responsibleUserID`,
`s_text`
FROM rusfishcom.`amo.tasks` $1;';
let vDelete_Records_Code= // опишите загрузку первичных ключей из источника. Используйте $(vPrimary_Key) вместо указания первичного ключа
'SQL SELECT
`$(vPrimary_Key)`
FROM rusfishcom.`amo.tasks`;';
call Inc_Load;
Код подпрограммы (нужно вставлять где-нибудь в начале скрипта, до загрузки данных)
sub Inc_Load_Full_Reload
trace Выполняется полная перезагрузка данных;
[$(vInc_Load_Store_Name)]:
$(vTable_Source(where 1=1));
Inc_Load_MaxDate: load
num(max(date#(FieldValue('$(vTS_Field)',recno()),'$(vTS_Format)'))) as Inc_Load_MaxDate
AutoGenerate FieldValueCount('$(vTS_Field)');
let vInc_Load_MaxDate=replace(peek('Inc_Load_MaxDate',0,'Inc_Load_MaxDate'),',','.'); drop table Inc_Load_MaxDate;
Comment table [$(vInc_Load_Store_Name)] with "MaxTS:$(vInc_Load_MaxDate)";
Store [$(vInc_Load_Store_Name)] into [$(vStore_Path)] (qvd);
if vDrop_Table=1 then
drop table [$(vInc_Load_Store_Name)];
end if
end sub
sub Inc_Load
let vInc_Load_Store_Name=SubField(subfield('$(vStore_Path)','.qvd',1),'/',SubStringCount('$(vStore_Path)','/')+1);
Trace vInc_Load_Store_Name=$(vInc_Load_Store_Name);
let vInc_Load_File_Exists=0;
////Проверка наличия файла в пути сохранения
for each vStore_Path_Exist in FileList ('$(vStore_Path)');
let vInc_Load_File_Exists=vInc_Load_File_Exists+1;
next
if NoOfRows(vStore_Path_Exist)>0 or vFull_Reset=1 or vInc_Load_File_Exists=0 then
call Inc_Load_Full_Reload;
else
Inc_Load_MaxDate:
LOAD
subfield("Comment",':','2') as Inc_Load_MaxDate
FROM [$(vStore_Path)]
(XmlSimple, table is QvdTableHeader);
vInc_Load_MaxDate_Data=replace(peek('Inc_Load_MaxDate',0,'Inc_Load_MaxDate'),',','.'); drop table Inc_Load_MaxDate;
vInc_Load_MaxDate_Data=$(vTS_Where_Format(vInc_Load_MaxDate_Data));
if len(vInc_Load_MaxDate_Data)=0 then
Trace !!!
Файл найден, но в нем нет сохраненной метки последней перезагрузки.
Выполняется полная перпезагрузка
!!!;
call Inc_Load_Full_Reload;
else
trace Выполняется загрузка обновленных данных
$(vTable_Source(where $(vTS_Field_Format($(vTS_Field)))>=$(vInc_Load_MaxDate_Data)));
[$(vInc_Load_Store_Name)]:
$(vTable_Source(where $(vTS_Field_Format($(vTS_Field)))>=$(vInc_Load_MaxDate_Data)));
Concatenate([$(vInc_Load_Store_Name)]) load * from [$(vStore_Path)] (qvd) where not Exists([$(vPrimary_Key)]);
if vDelete_Records=1 then
inner join ([$(vInc_Load_Store_Name)]) load *;
$(vDelete_Records_Code);
end if
Inc_Load_MaxDate: load
num(max(date#(FieldValue('$(vTS_Field)',recno()),'$(vTS_Format)'))) as Inc_Load_MaxDate
AutoGenerate FieldValueCount('$(vTS_Field)');
let vInc_Load_MaxDate=replace(peek('Inc_Load_MaxDate',0,'Inc_Load_MaxDate'),',','.'); drop table Inc_Load_MaxDate;
Comment table [$(vInc_Load_Store_Name)] with "MaxTS:$(vInc_Load_MaxDate)";
Store [$(vInc_Load_Store_Name)] into [$(vStore_Path)] (qvd);
if vDrop_Table=1 then
trace Идет удаление строк, отсутствующих в источнике;
drop table [$(vInc_Load_Store_Name)];
end if
end if
end if
set vStore_Path_Exist=;
end subВыводы
Теперь можно быстро внедрить инкрементальное обновление без необходимости писать сложный код поддержки разных сценариев загрузки, и дублируя запросы под инкремент/не инкремент. А также беспокоиться о поддержке переменных с метками времени.
Евгений спасибо, очень облегчаете обучение Qlik.
Опечатки: измененились , контроллировать , должено , синтаксие , помошью , должено , перпезагрузка
Добрый день.
Не работает скрипт.
Добрый день. Не могу подтвердить. У нас работает, как и у нескольких сторонних пользователей.
Добрый день.
Прошу прощения, да скрипт рабочий. Но пришлось немного где-то дописать от себя.
Вопрос такой, зачем в данном блоке используем RecNo()? Нам ведь нужно получить метку даты в 5-значных цифрах. И для чего нужен AutoGenerate FieldValueCount? Вроде далее это нигде не используем.
Inc_Load_MaxDate: load
num(max(date#(FieldValue(‘$(vTS_Field)’,recno()),’$(vTS_Format)’))) as Inc_Load_MaxDate
AutoGenerate FieldValueCount(‘$(vTS_Field)’);
Кстати, этот блок у меня не работал, добавил resident.
Inc_Load_MaxDate: load
num(max(date($(vTS_Field),’$(vTS_Format)’))) as [Inc_Load_MaxDate]
resident [$(vInc_Load_Store_Name)];
Этой штукой мы получаем максимальное значение таймстампа в поле с датой изменения. Эта конструкция:
load FieldValue(Поле,recno()) autogenerate FieldValueCount(Поле); Позволяет получить все уникальные значения поля, используя отбор из индексной таблицы, а не перебор значений из исходной таблицы. Потом он помещается в переменную и пишется в комментарий QVD таблицы, чтобы потом оттуда быть прочитанным и использоваться как точка отсчета для загрузки обновленных данных. Мне сложно сказать, как у вас сейчас работает код после внесенных исправлений)
Все, теперь понял.
Классный скрипт. Спасибо большое.
Добрый день.
Не понятна запись FROM rusfishcom.`amo.tasks` $1;’;
rusfishcom. — это база для подключения.
А что такое `amo.tasks` ???
rusfishcom — база. amo.tasks — Таблица в базе
Добрый день! Большое спасибо за скрипт. Все заработало. Правда, не с первого раза, но тут адаптация запроса к базе.
Здравствуйте Евгений!NoOfRows(vStore_Path_Exist)>0
Здравствуйте Евгений!
Не могли бы вы пояснить следующее условие для полной перезагрузки NoOfRows(vStore_Path_Exist)>0 ?
Что NoOfRows() должна вернуть в данном случае?
Это условие проверяет существование таблицы. Нет строк — нет таблицы 🙂