Если описать ситуацию одной картинкой, то она выглядит так:

Причем речь не о источниках данных. А о той среде, которую создает себе аналитик для решения своих задач.
Аналитики делают в своих BI-системах дашборды на разрозненных данных, создавай красивые витрины для неудобных, не документированных и не структурированных источников.
Пока приложений и наборов данных не много, такой подход кажется весьма рабочим. Проблемы начинаются, когда появляется потребность анализировать большое кол-во таблиц, а также непредсказуемо расширять ваши приложения.
Откуда берется хаос в аналитике
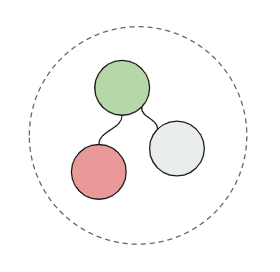
Представим, что вам нужно создать приложение для аналитики продаж. Вы получаете SQL-запросом данные по продажам, пару справочников. В результате, получается такая аналитическая структура:
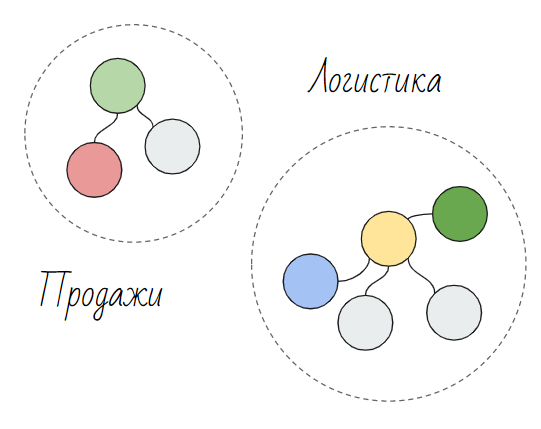
Позже, вам поручают создать аналитику для логистов. В нем будет другой набор данных, но в том числе и данные по продажам. Однако, для решения задач логистов, вам потребуется в данных по продажам иметь другой набор полей. Вы также получаете данные по продажам через SQL-запрос. Теперь у вас в 2-х приложениях есть данные по продажам, которые отличаются некими параметрами.
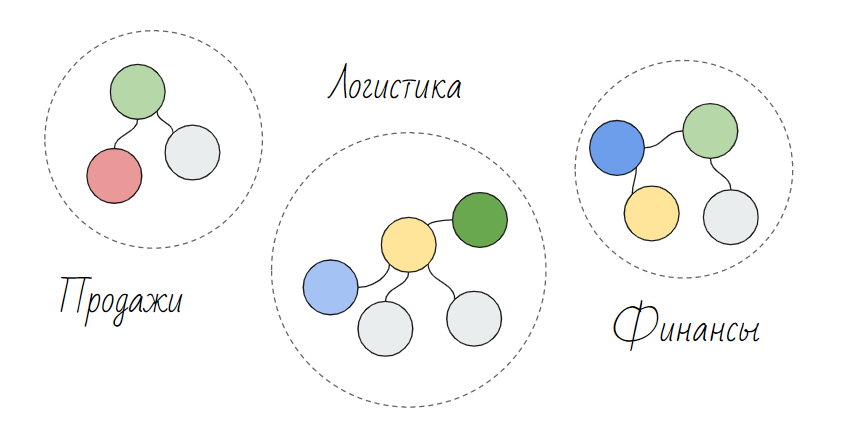
Спустя время, вам нужно сделать аналитику финансов. Вы также получаете SQL-запросами очередную вариацию данных по продажам.
Проблема такого подхода в том, что вы формируете изолированные аналитические сущности. Самый запущенный пример — это эксель отчеты. Каждый эксель-файл — это изолированный набор данных, который может быть визуализирован строго в рамках той структуры данных, которая в него выгружена. Нельзя детализировать данные в нем глубже, агрегация данных в таблице (если в Excel нет детализации до чеков в продажах, вы их и не увидите).
BI-системы облегчают эту ситуацию, потому что как минимум позволяют делать нужные агрегации данных налету. Но проблема с созданием большого кол-ва дубликатов одних и тех же сущеностей, но с немного разнымипараметрами остается.
У вас запросто может быть несколько разных SQL запросов для получения одних и тех же, или немного отличающихся данных, и все это приходится поддерживать.
Самое главное, у вас нет понимания, какой итоговый набор данных доступен для анализа, и какие сценарии анализа вам в целом доступны. Потому вы видите только изолированные модели данных, и единой карты аналитического ландшафта просто не существует.
Сложности могут быть и при дальнейшем масштабировании ваших приложений, т.к. при первоначальной постановке задачи не было обозначено, что в будущем нужно будет добавить новые таблицы, и вы просто не предусмотрели это в первоначальной структуре приложения.
Аналитический ландшафт
Правильный подход заключается в том, чтобы создать чистовые максимально полные представления анализируемых данных, так называемые аналитические таблицы. И при построении приложений брать данные только из этой структуры.
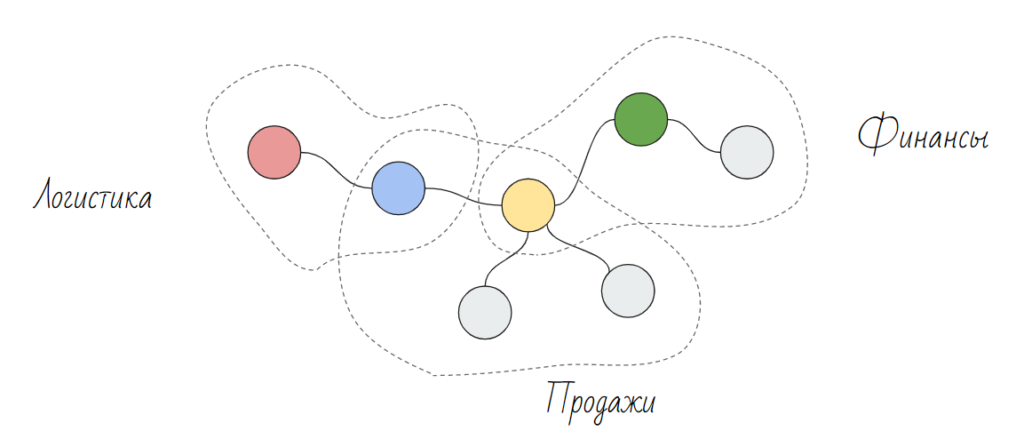
Так вы сможете видеть весь перечень доступных для анализа данных со всеми возможными разрезами, легко масштабирвоать ваши приложения и вести справочную информацию по данным.
Обычно для такого используются платформы DWH (Data Warehouse). Возможно, у вас в компании он уже имеется. Однако практика показывает, что наличие DWH не гарантирует удобное для управления хранение данных. А самое главное — вам могут потребоваться аналитические признаки, которых в DWH просто нет. Например, какое-нибудь поле, расчитанное по сложной логике. Можно заказать его создание в службе, отвечающей за DWH, но ожидание скорее всего окажется слишком долгим.
Поэтому у разработчиков на Qlik есть огромное преимущество — они могут создать целостный аналитический ландшафт полностью совершенно самостоятельно. И сделать это намного быстрее, чем на любых DWH-альтернативах. Именно этому и посвящен данный мини-курс.