Возможно вам знакома ситуация: фактические данные содержат идентификатор, ведущий на справочники. Например, ИД сотрудника. Справочник сотрудников помимо имен людей содержит некие оргструктурные разрезы. Что-то вроде такого:
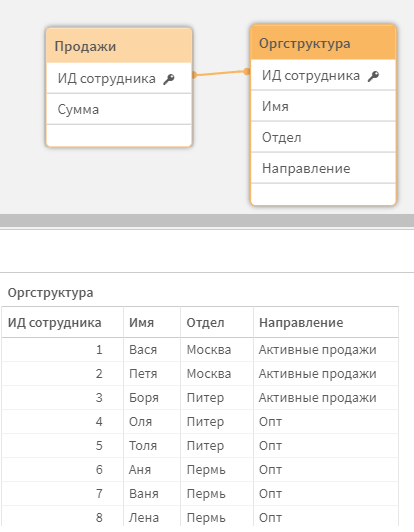
И вот однажды финансовый отдел присылает вам данные оперплана — и они посчитаны в разрезе, например, Отделов.
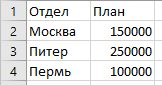
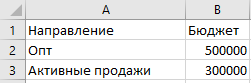
А вдогонку, еще и данные по бюджету, но в разрезе направлений.
Если у вас достаточно сложная модель данных (не как в нашем примере), то не получится просто взять и загрузить данные, а потом сопоставить их друг с другом. Вы столкнетесь с необходимостью иметь несколько однотипных полей, вроде «Направление-бюджет» и «Отдел-оперплан». Или в таблицу связей придется выносить поля Направление и Отдел, хотя изначально было достаточно вынести только ИД сотрудника.
Кроме того, в самом справочнике оргструктуры могут быть другие группировки, которые должны также сохраняться для анализа оперплана и бюджета.
Чтобы вся эта история не закончилась переносом всего справочника в таблицу связей, нужно воспользоваться техникой создания справончика универсальной гранулярности.
Создаем справочник универсальной гранулярности
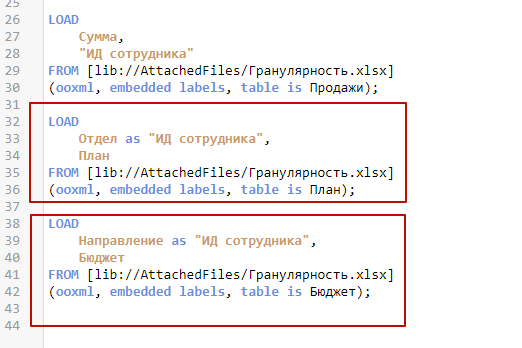
Логика создания проста: у нас уже есть справочник сотрудников со всеми нужными разрезами. Нужно чтобы оргструктурные разрезы других сценариев тоже присоединялись к нему как ИД сотрудников, наследуя все соответствующие свойства.

Можно завести техническое поле «Гранулярность», в котором вы будете подписывать, какому уровню агрегирования соотетствуют данные записи.
Как итог, в справочнике появятся записи, содержащие оргструктурные свойства, но в качестве ИД пользователей имеющие наименования укрупненных группировок.
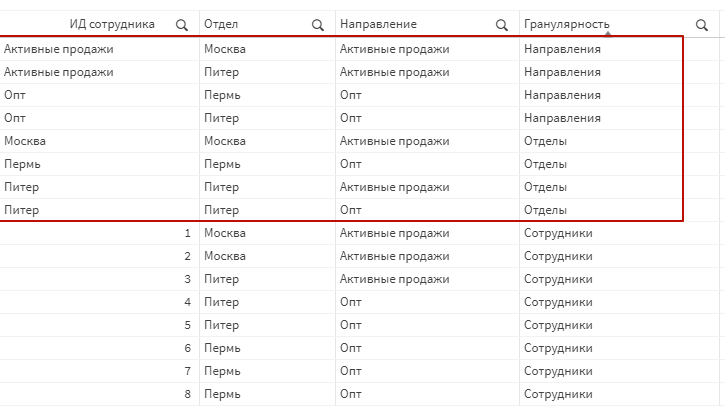
Данные к такому справочнику теперь могут подключаться по единому полю ИД сотрудника. Естествено, для агрегированных таблиц в качестве ИД сотрудника выступают разрезы Отдел и Направление.
Результат: мы можем одним с одним справочником визуализаровать фактические данные разной гранулярности.

Будьте внимательны с группировками: если напутаете с разрезами (например, план у нас задан по отделам, а отдел Питер имеет сразу 2 направления: Активные продажи и Опт),

то при визуализации данных получите несовпадение итогов при выводе разреза, включающиим несколько подуровней. Так, при визуализации в разрезе направлений показатель план будет относить Питер и к Активным продажам, и к Опту. При этом на уровне итогов сумма будет веравно верной.

Выводы
Такая методика хорошо подходит для комбинирования данных разной гранулярности без переусложнения модели данных. Особенно хорошо подход работает для всяких хитрых разрезов, которых нет в системах-источниках. Зато есть во всяких особых управленческих экселях.
Уделяйте особое внимание пересечению разрезов (как Активные продажи и Опт в Питере). Возможно, вам нужно будет создать составные ключи для правильного разноса данных в соответствующие группы. Например, если мы знаем что планы ставятся только по активным продажам, для планов по питеру можно создать ИД сотрудника типа «АП|Питер» для активных продаж. И к нему привязывать данные плана. Таким образом вы избежите путаницы в отображении данных в некоторых разрезах.