Во время написания скриптов подготовки данных часто приходится заниматься отладкой. Проверять, как взаимодействуют между собой запросы к различным источникам, проверять результаты вычислений, корректность маппингов, да и вообще много чего.
Проблема в том, что в в Qlik нет готовых инструментов для контроля выполнения запросов — постоянно приходится создавать временные контрольные таблицы, exit script, комментировать блоки кода, создавать проверочные визуализации. Поэтому мы разработали приложение, которое облегчает эту рутину. Давайте пройдемся по нему.
Просмотр таблиц
Чтобы быстро посмотреть, какие данные у нас получились на выходе, можно воспользоваться конструктором.
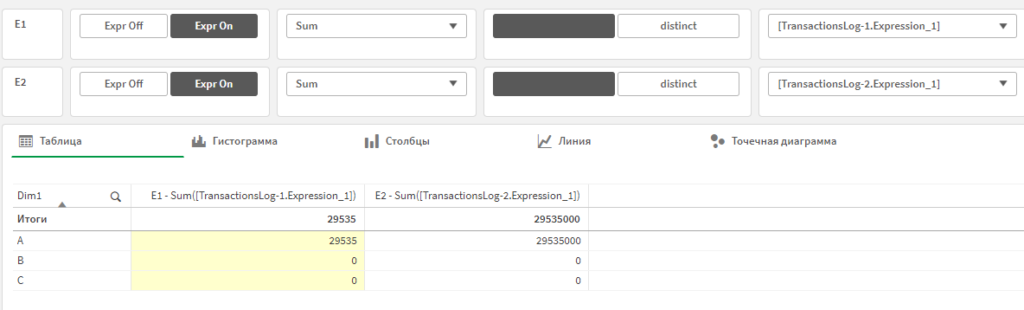
Он позволяет вывести в таблицу до 10 полей-измерений, и 2 меры с простой формулой. Список полей берется из текущей модели данных. Обычно этого достаточно для проверок, и при этом не нужно собирать таблицу руками.
Если выбрать одно поле-измерение, можно посмотреть распределение его значений на гистограмме (если значения числовые).
Если включен вывод меры и выбрано одно измерение, можно посмотреть значение меры по измерению на линейной или столбчатой диаграмме.
Если включено одно измерение и 2 меры, можно посмотреть их на пузырьковой диаграмме.
Однако, это не самая интересная часть приложения) Мы также заготовили несколько подпрограмм, которые облегчают работу на уровне скриптинга.
Обратная квалификация
Нейминг полей крайне важен в Qlik. Наиболее простой функционал для систематизации имен — квалификация. Однако им не удобно пользоваться во время формирования таблиц чередой последовательных запросов. Префиксы от имен временных таблиц будут все портить, часть полей придется исключить из квалификации, чтобы делать по ним объединение.
Все это привносит еще больший хаос, чем был изначально)
Подпрограмма ReverceQualify позволяет задать полям уже существующей таблицы модели данных выбранный вами префикс.

У подпрограммы есть 4 параметра:
- Название таблицы в модели данных;
- Желаемый префикс;
- Поля, имена которых не надо квалифицировать. Перечисляются через разделитель «|», могут содержать знаки подстановки для Wildmatch. Например, обозначение поля @* исключит из переименования все поля, начинающиеся с @.
- Строка для замены на пробел. Позволяет изменить в итоговых именах полей произвольный символ или их набор на пробел. Для таблиц, предназначенных для использования в визуализациях, предпочтительно разделение слов в названиях именно пробелами. Однако в разработке удобно, когда поля названы вроде «название_поля». С помощью четвертого параметра можно преобразовать разделители слов из технических в бизнесовые

Особенность работы подпрограммы в том, что переименование произойдет независим от от того, уникальные ли названия полей в целевой таблице или нет. Если переименовывать нужно поля, являющиеся уникальными в текущей модели, то процесс пройдет через команду rename field, что не займет дополнительного времени.
Если переименовываемое поле также содержится в другой таблице в текущей модели, то переименование произойдет через перезагрузку целевой таблицы через resident. Что займет время, но даст нужный результат.
Контрольные слепки таблиц
Порой недостаточно посмотреть на финальную таблицу для понимания проблем. Иногда требуется понимать, как изменяются данные, проходя через несколько этапов.
Для этого есть подпрограмма ETLCheckpoints. Она позволяет создать квалифицированный слепок целевой таблицы, и построить между ними связь по ключевому полю, для отслеживания изменений в не ключевых полях между слепками.
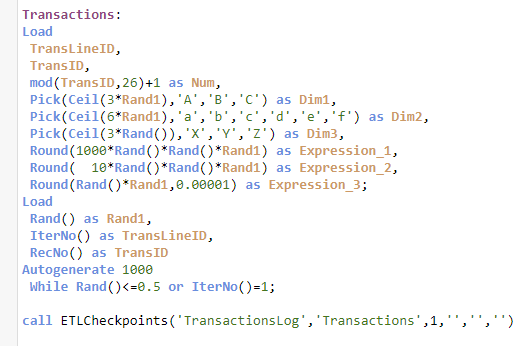
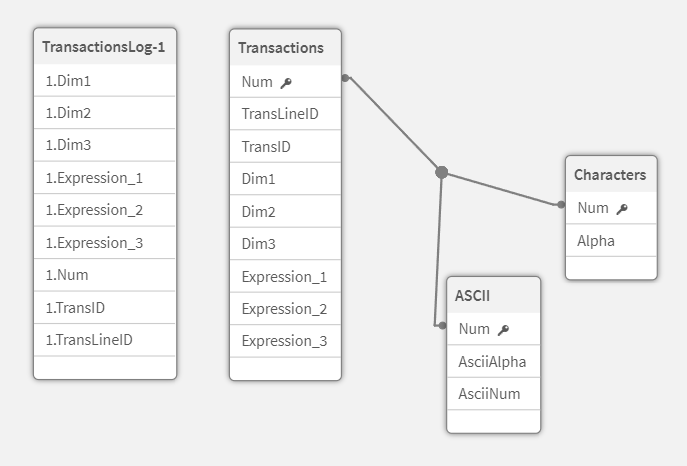
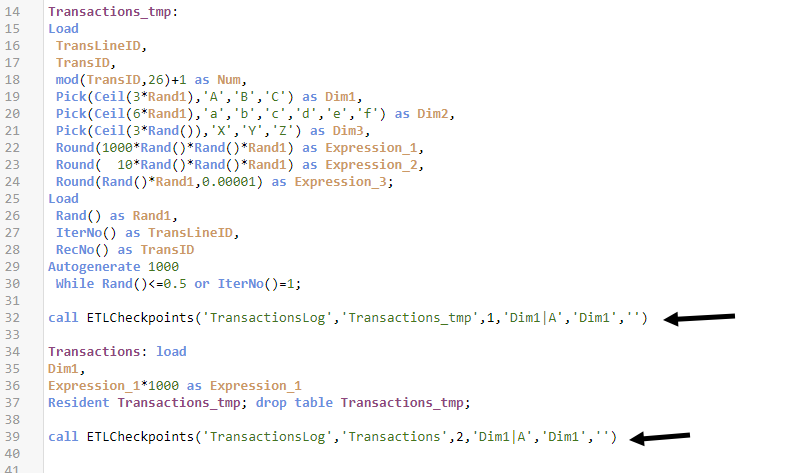
Вызывая подпрограмму, вы можете создать слепок состояния таблицы в данный момент времени, не модифицируя сам скрипт. Подпрограмма содержит 6 параметров:
- Название слепка. Будет использоваться для именования таблиц слепков;
- Название таблицы модели, для которой делается слепок;
- Порядковый номер слепка. Число. Здесь вы можете указать нумерацию при вызове подпрограммы для понимания последовательности формирования таблиц. Также номер идет в название таблицы слепка, для гарантии уникальности. Этот параметр можно использовать для создания последовательности слепков таблиц, разнесенных между разными приложениями.
- Ограничитель записи в слепке. Может работать в 3-х режимах. Если пустой, то в слепок загрузятся все записи таблицы. Если указано число X, то в слепок загрузятся первые X записей через first X load. Также можно указать комбинацию ‘Поле|Значение1|…|*ЗначениеWildmatch*’. В этом случае в слепок попадут значения, отфильтрованные по полю. При этом для значений можно указывать варианты с подстановкой символов для wildmatch. Удобно для мониторинга преобразований на контрольной выборке.
- Ключевое поле/поля. Перечисляется как строка со списком полей. При необходимости поля надо брать в квадратные скобки, например: ‘Поле1,[Поле 2]’. Имена должны быть таблице источнике для слепка, и будут продублированы в слепке в неизмененном виде. Удобно для просмотра процесса изменения данных в разрезе конкретного поля.
- Путь сохранения слепка. Если не указан, то слепок остается в модели. Если указан, слепок сохраняется в файле, создавая там подпапку с именем слепка, и QVD файла итерации слепка. При этом слепок из модели удаляется.
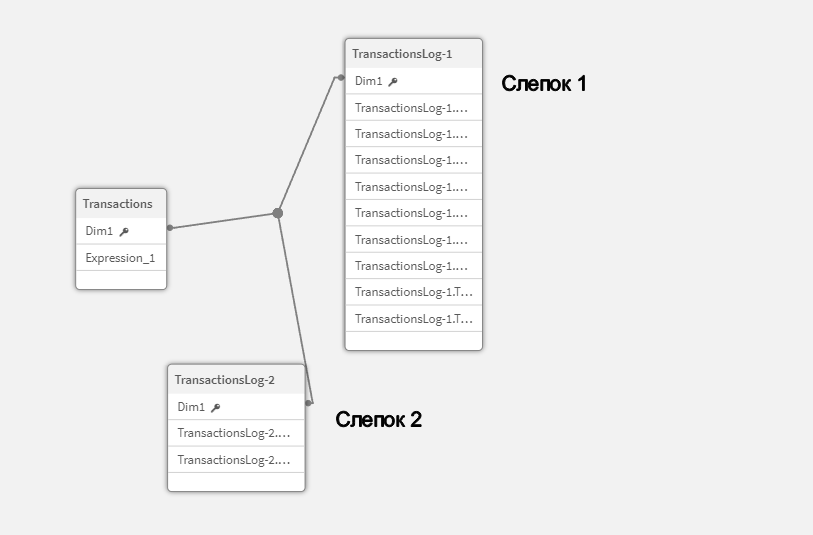

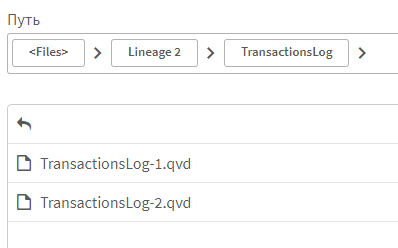
Вы можете использовать слепки как для отладки сложных алгоритмов преобразования, так и для хранения справочной информации о процессах преобразования данных.
Удаление всех таблиц, кроме списка
Подпрограмма KeepTables удаляет из модели все таблицы, кроме тез что перечислены в ее единственном параметре. Мы уже публиковали похожую подпрограмму раньше. Ключевое отличие этой — можно указывать не только явные имена таблиц, но и условия для широкого соответствия (wildmatch). Названия таблиц разделяются «;»
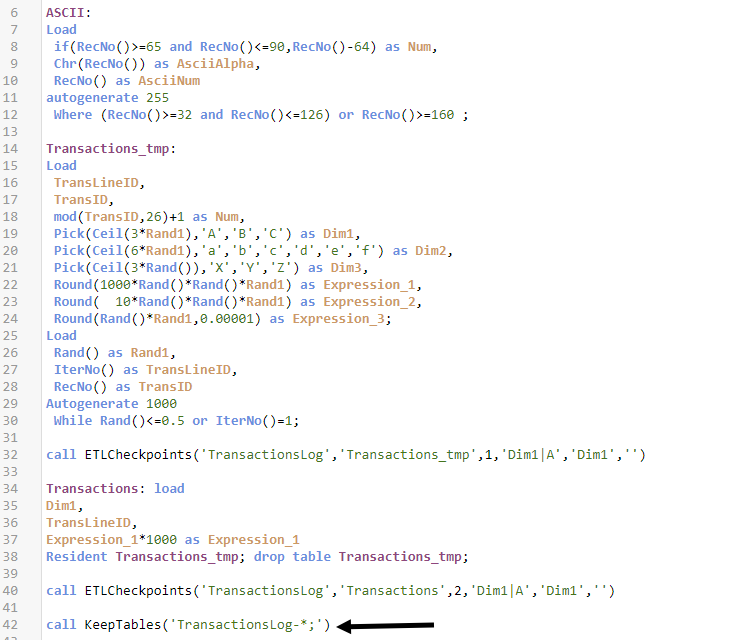
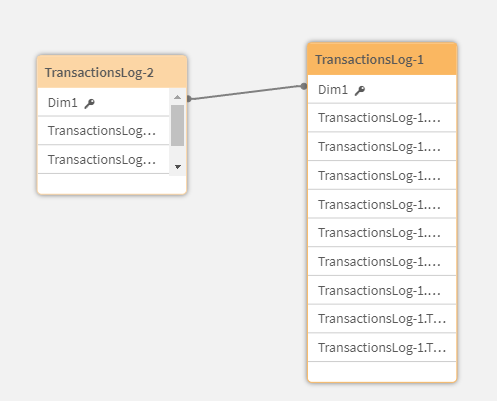
Как видите, эту подпрограмму удобно использовать для быстрой очистки множества таблиц в ETL-процессе, или для отладки скрипта в произвольной точке, с удалением лишних таблиц.
День добрый.
Тема интересная, но не уловил мысль разработки.
Нет видеоматериала, может мне так понятнее будет?
Здравствуйте. Видео к сожалению нет. Можете задать вопрос по непонятной части.