Цели занятия:
- Научиться извлекать из данных больше инсайтов за счет создания контекста для сравнения;
- Научиться настраивать логику работы фильтров.
Что такое «контекст» и зачем он нужен
На прошлых занятиях мы сделали простенький дашборд. Напомню, он выглядит так:
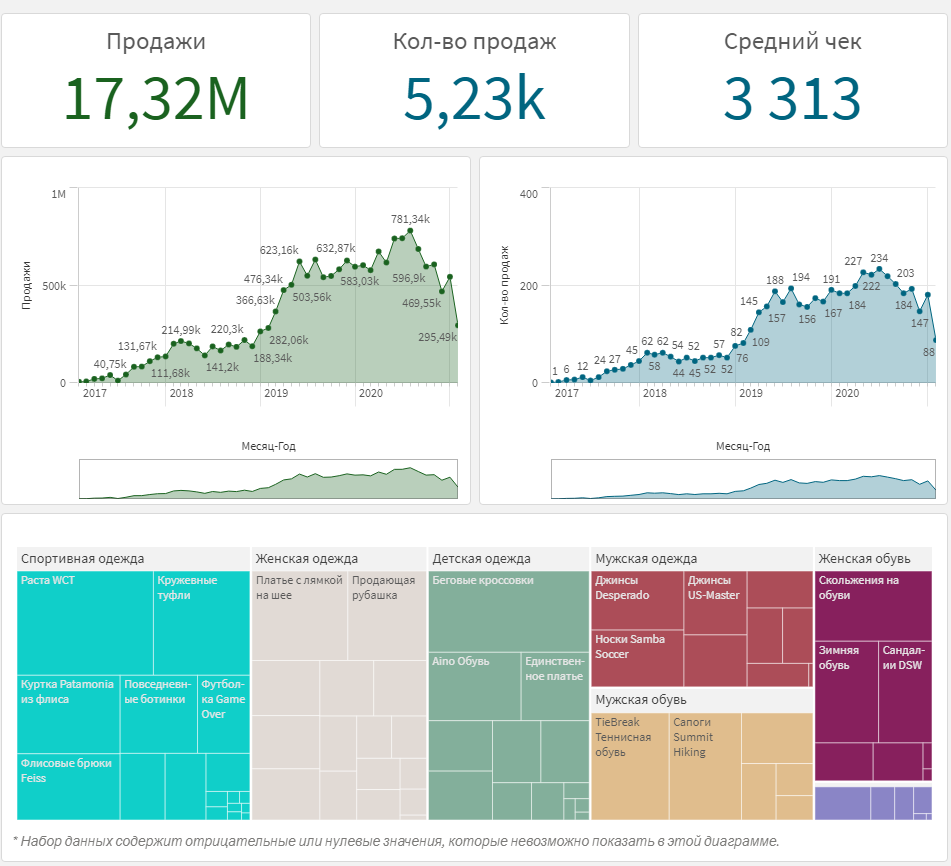
Дашборд простой именно для учебных целей. Но как хорошие аналитики, мы знаем — чтобы числа на экране обрели смысл, нужно задавать им контекст. Обычно контекст задается через сравнение с другими показателями. Например, в 2020 году продажи 7,7 млн. Это хорошо или плохо? Мы можем сравнить продажи 2020 с продажами 2019, и у видеть, что превзошли прошлый год на 1,7 млн, что выглядит неплохо.

В качестве контекста используются сравнения между разными периодами, сегментами (клиентскими, продуктовыми), плановыми значениями.
Чтобы делать аналитику план/факт, нужно овладеть техниками создания более сложных моделей данных, и это будет в следующих занятиях.
А сейчас мы научимся создавать универсальный контекст для сравнения из текущих данных модели.
Альтернативные состояния
Создайте новый лист.
Скопируйте с первого листа элементы: KPI Сумма продаж, График с суммой продаж, блок фильтров. На новом листе продублируйте эти элементы, чтобы они копии занимали 2 половины экрана.
Элементы можно копировать через Ctrl+C, вставлять из Ctrl+V.
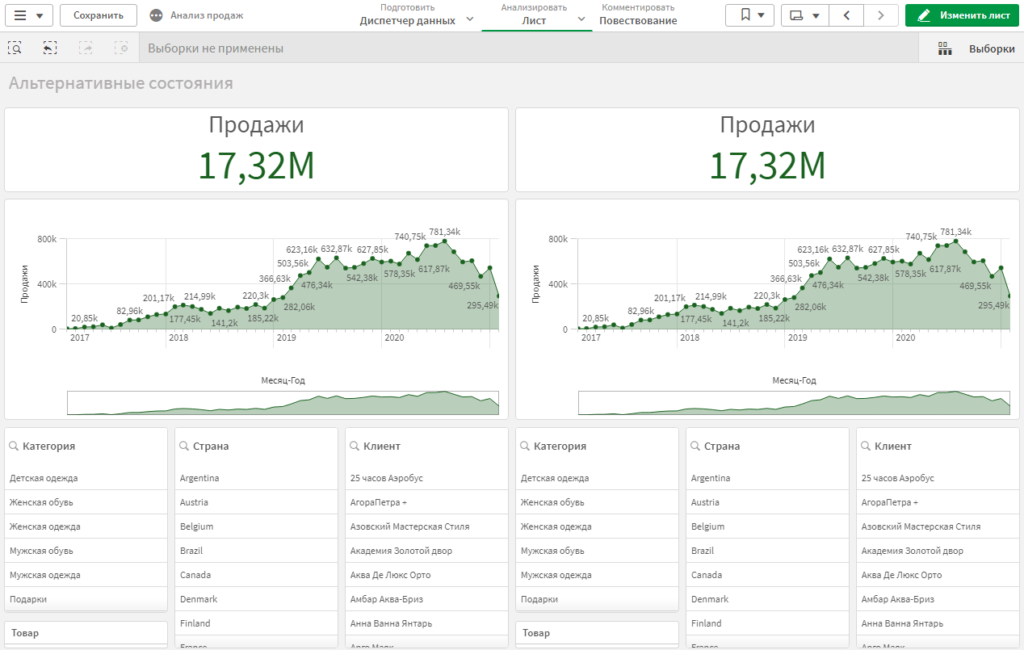
Установите несколько любых фильтров в левой части. Убедитесь, что они работают синхронно с правой частью. Еще бы, ведь справа у нас копии одних и тех же элементов, с одними и теми же настройками.
Сбросьте фильтры с помощью кнопки на панели выборок.

Теперь, перейдите в режим редактирования листа, и на панели элементов слева откройте Основные элементы > Другие состояния > Создать.
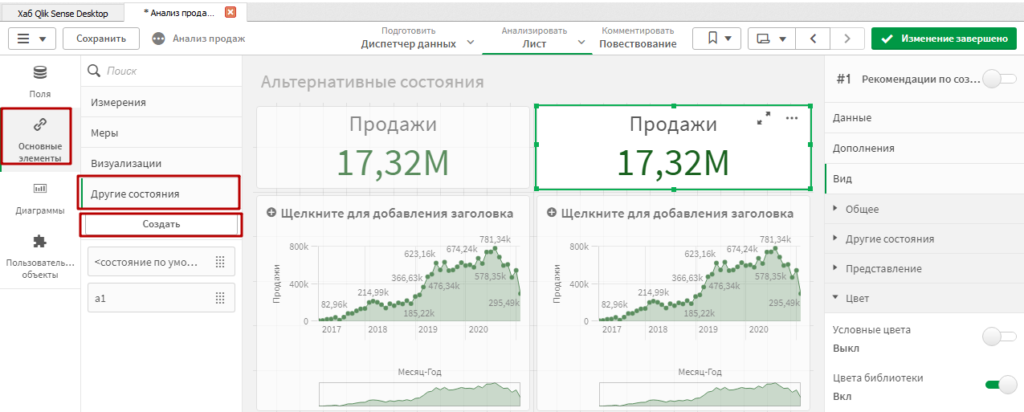
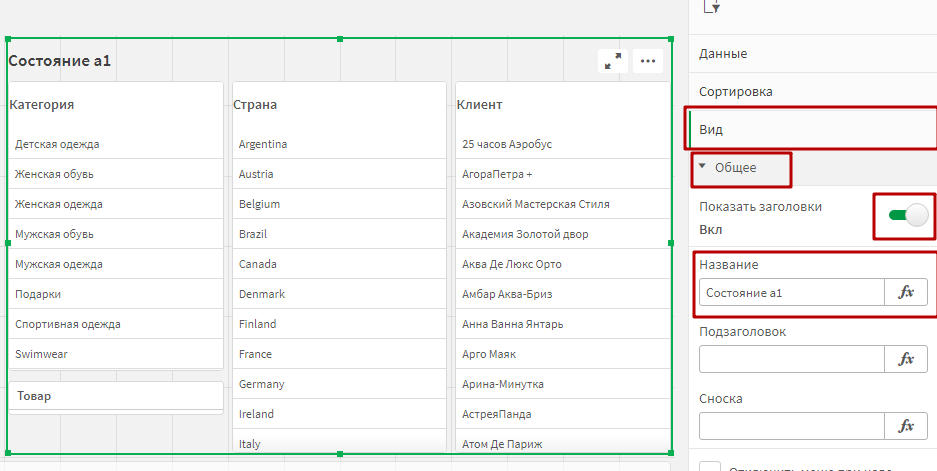
Создайте новое состояние, назвав его «a1». Вообще, вы можете называть состояния как угодно, лишь бы вам было удобно.
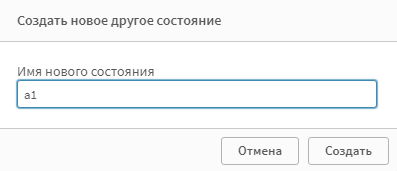
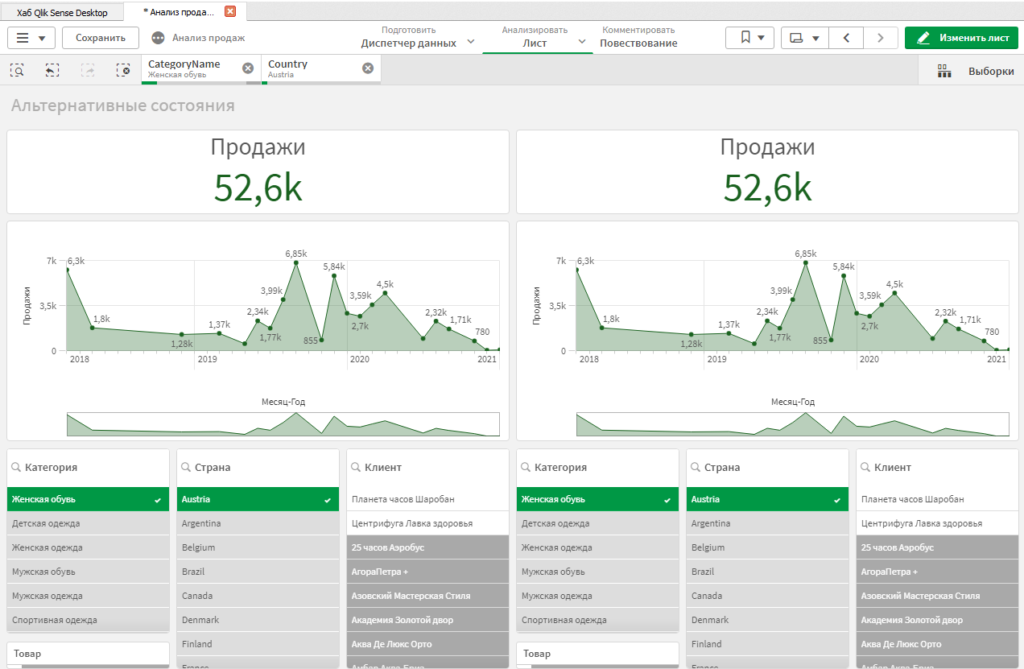
Выберите на листе правый KPI. В панели настроек справа, откройте разел Вид, а в нем подраздел Другие состояния. Такой раздел есть у всех элементов.
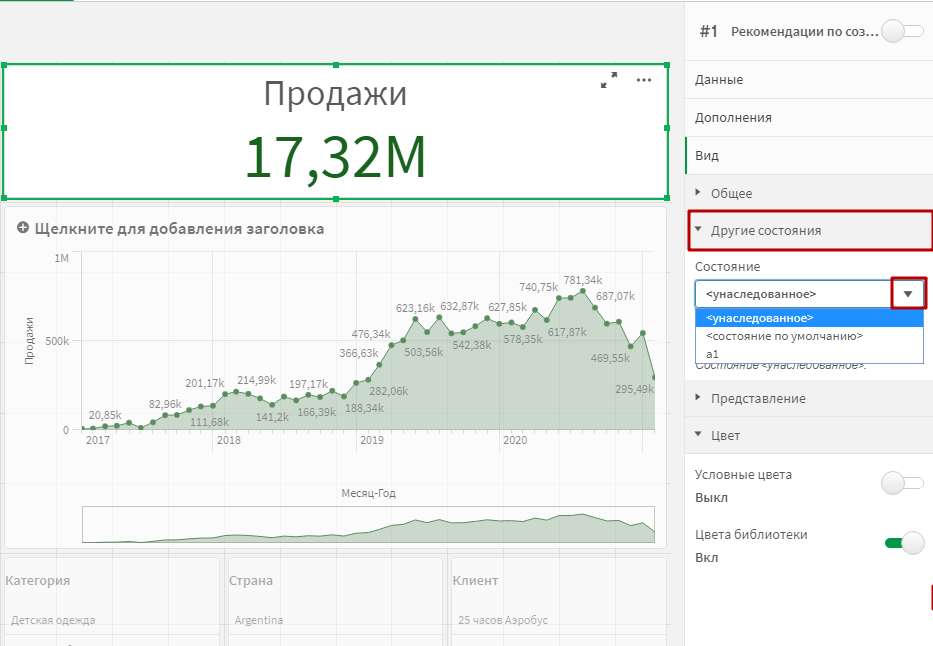
В выпадающем списке Состояние выбираем «a1». Повторяем эту процедуру для правого графика и правого фильтра.
Теперь, выберите категорию товара в фильтре слева. Мы видим, что данные в диаграммах слева отфильтровались, а справа — нет.
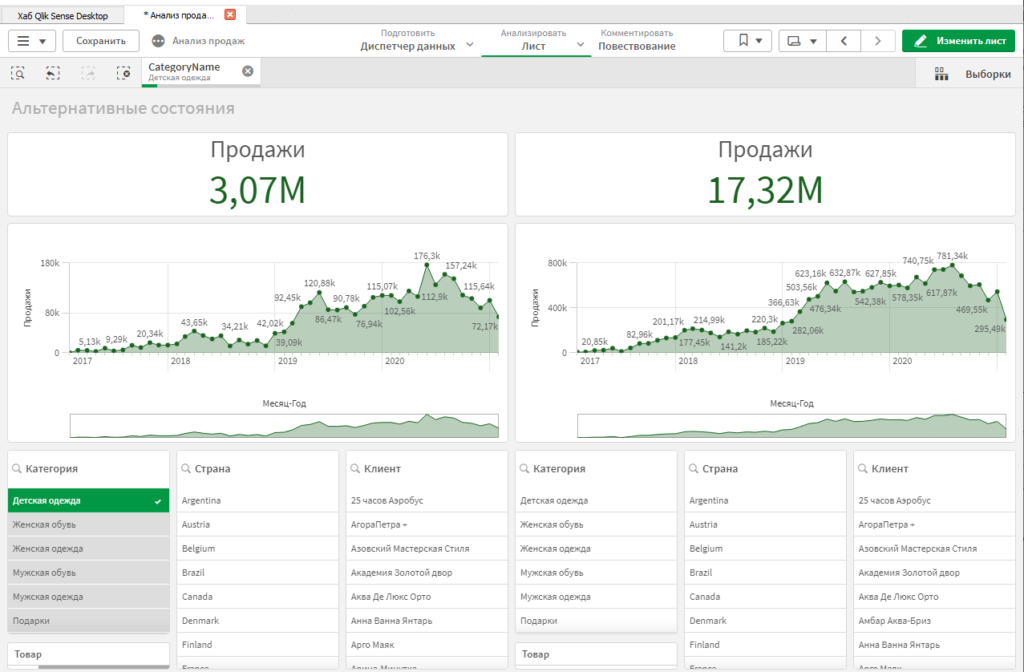
Выберите любую другую категорию в фильтр справа. Убедитесь, что фильтрация справа работает полностью независимо. Таким образом, мы можем задавать несколько наборов фильтров, используя их независимо друг от друга.

Как работают альтернативные состояния? По сути, они позволяют делать независимые запросы к модели данных. Как если бы у нас в приложении было бы несколько несвязанных между собой моделей данных.
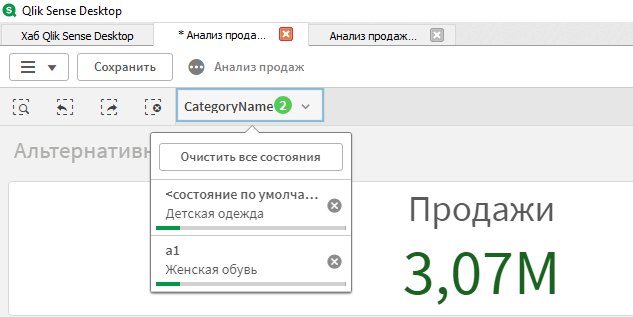
В приложении всегда присутствует «Состояние по умолчанию», которое задействуется, когда мы не указываем другое состояние для элемента. Если отбор в поле производится по нескольким состояниям, то мы увидим цветные кружки на панели фильтра, в зависимости от кол-ва задействованных состояний. При клике по фильтру в панели выборок можно увидеть отборы в разных состояниях, и изменить их.
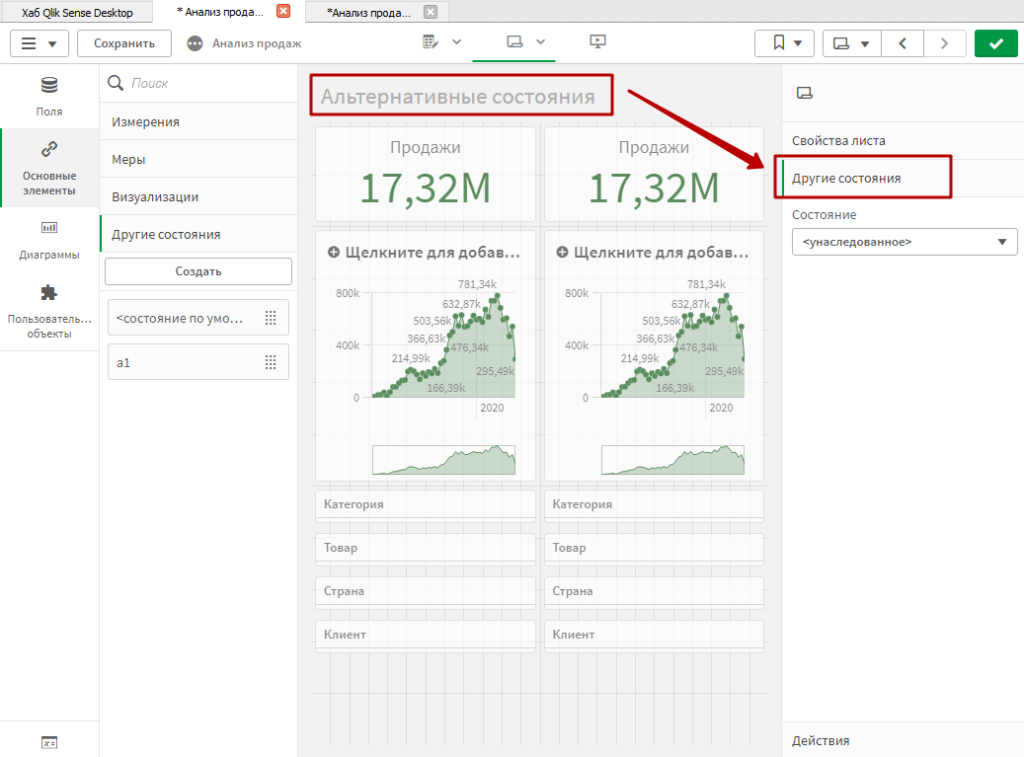
Альтернативные состояния могут применяться к элементам визуализации, как в нашем примере. Также, они могут быть применены целиком к листу.
Таким образом, все элементы на листе будут работать в альтернативном состоянии. Т.е. фильтры с этого листа не будут влиять на листы и элементы, находящиеся в других состояниях.
Также, альтернативные состояния можно использовать внутри формул.
Альтернативные состояния в формулах
Ок, мы научились делать графики, которые фильтруются независимо друг от друга. Но не всегда удобно, если сравниваемые элементы располагаются на разных диаграммах.
Создайте новый лист. Разместите на нем:
- График продаж;
- Блок фильтров в обычном состоянии;
- Блок фильтров в состоянии a1;
Эти элементы можно скопировать с предыдущего листа.
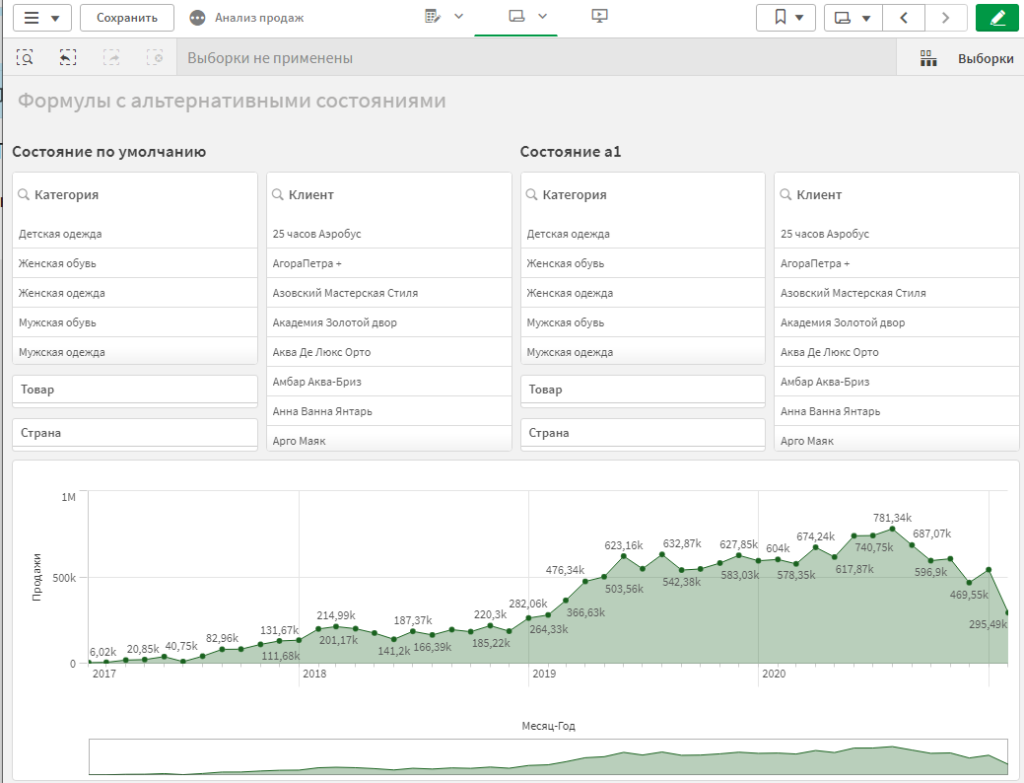
Для удобства, блокам фильтры можно в заголовках добавить подписи для опознавания.
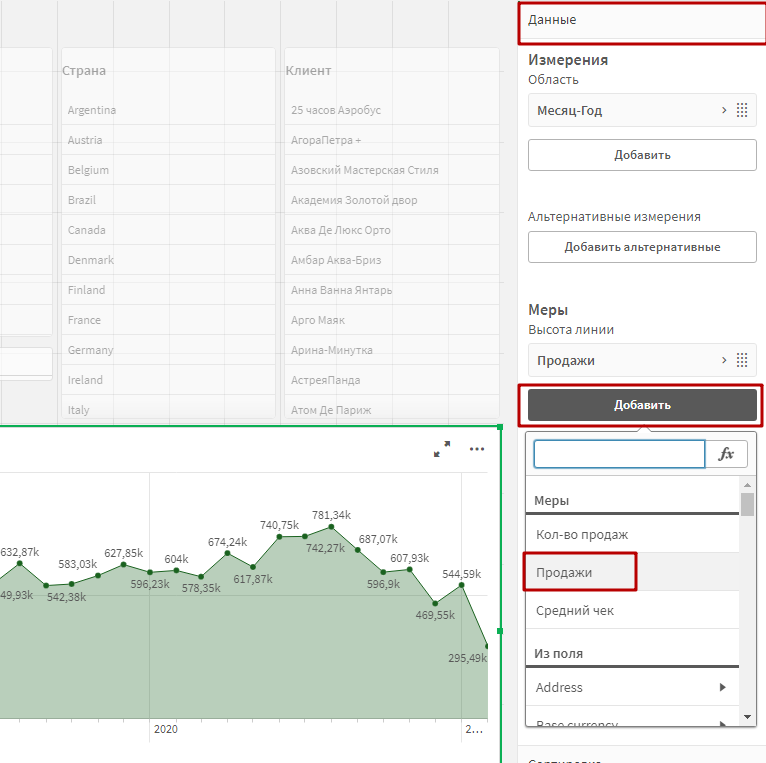
В настройках графика в разделе Данные добавьте вторую меру «Продажи».
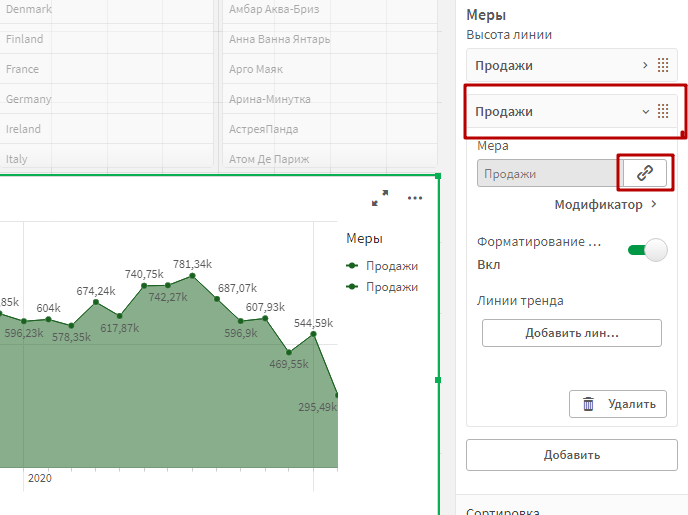
Зайдите в настройки второй меры, и открепите ее от библиотеки основных элементов, чтобы мы могли редактировать ее формулу.
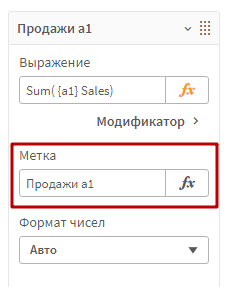
Зайдите в редактор выражений формулы, и пропишите {a1} внутир функции суммирования, перед названием поля.

В метку пропишите «Продажи a1», чтобы визуально отличать этот показатель.
Попробуйте установить разные фильтры в разных состояниях и убедитесь, что у вас отрисовываются разные графики по каждому набору фильтров.
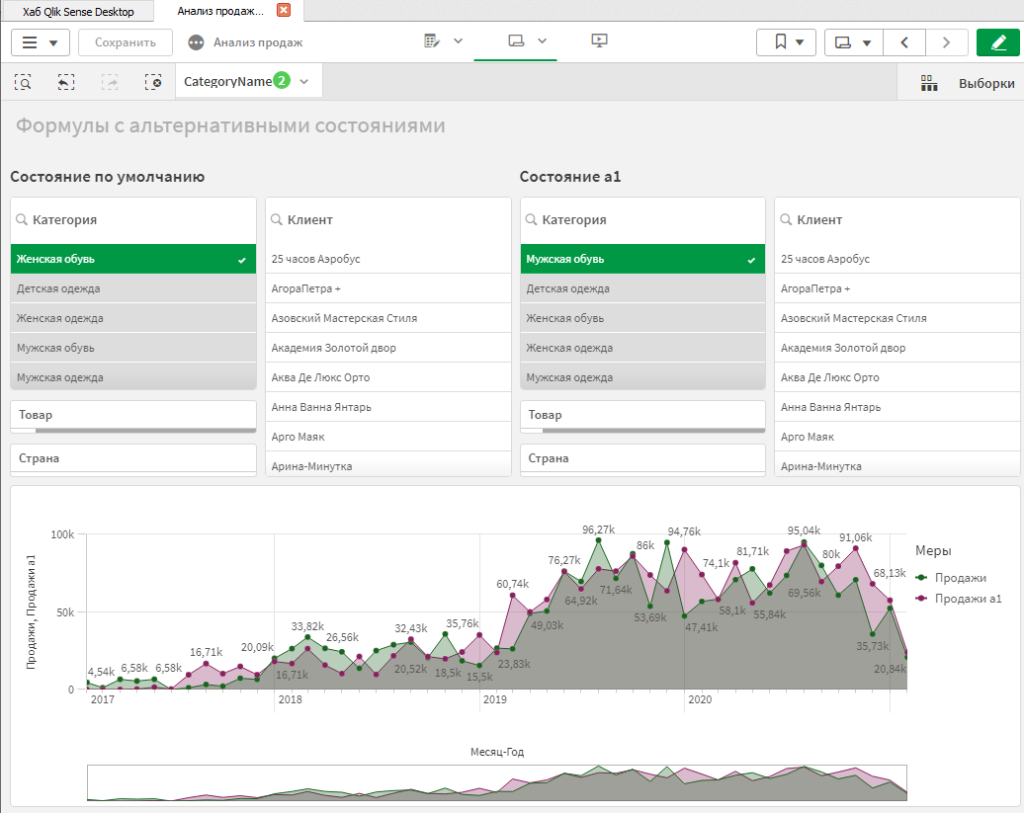
Как можно заметить, эта механика позволяет нам быстро организовать любые сравнения в любых аналитических разрезах, т.к. нам не нужно заранее предопределять поля, по которым должны работать эти раздельные отборы. Мы можем использовать любые поля модели в любом из состояний, и нам не нужно для этого программировать никакой сложной логики.
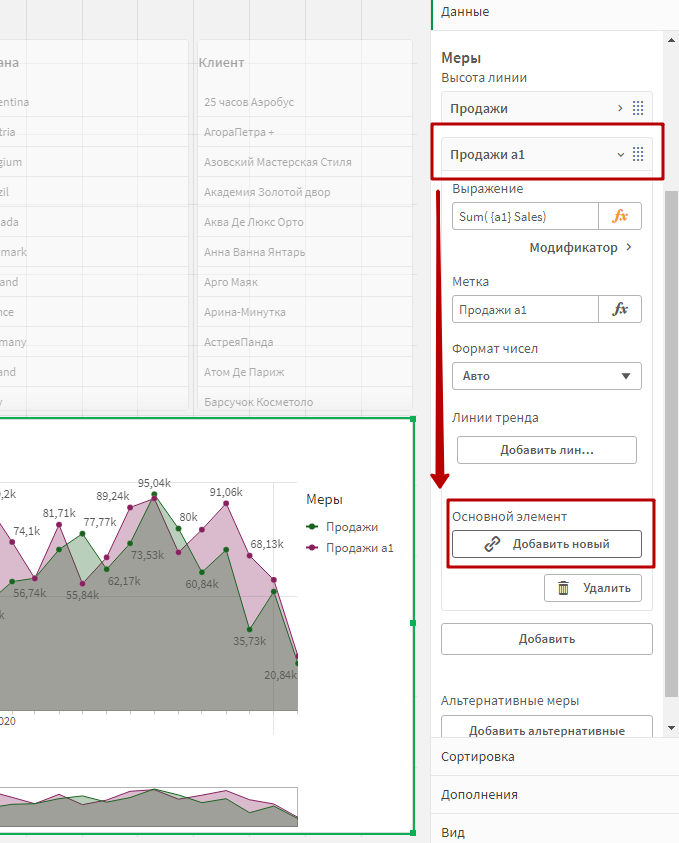
Давайте отработаем использование формул с разными состояниями в одном выражении. Для начала, сохраним нашу альтернативную меру продажи в основные элементы. Проще всего это сделать, раскрыв ее настройки на графике, и нажав кнопку «Добавить новый основной элемент»
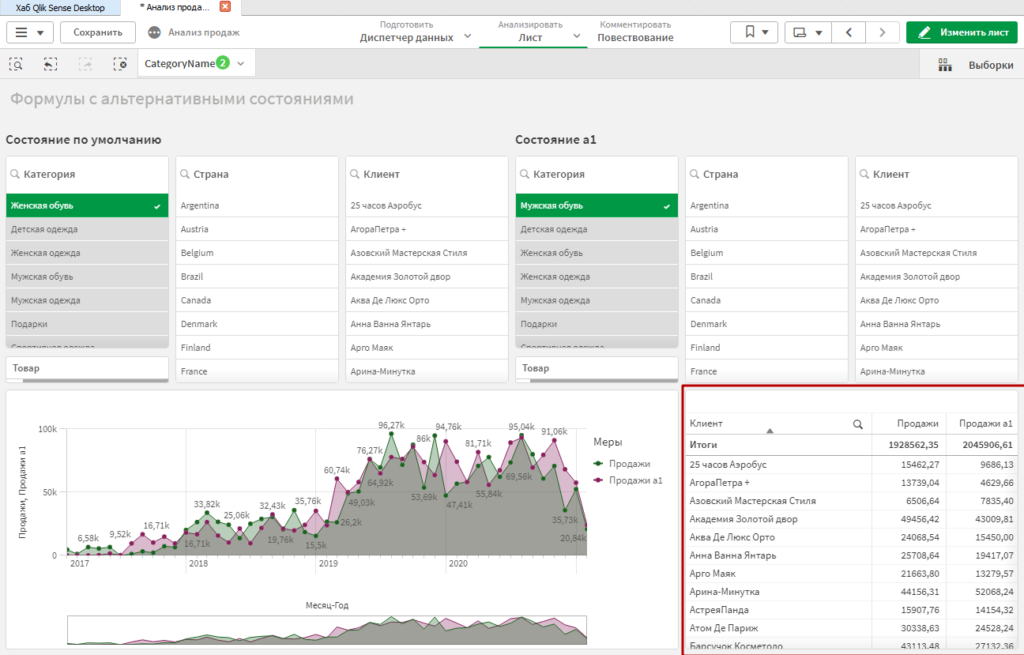
Сожмите немного график в нижней части листа, и добавьте туда элемент Таблица (не Сводная таблица, а просто Таблица).
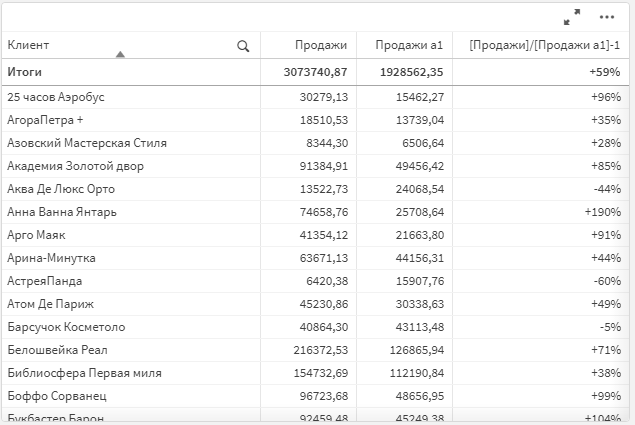
На ней разместите измерение Клиент, и меры Продажи и Продажи a1.
Добавьте на таблицу новый столбец — Меру. Перейдите в редактор выражений.
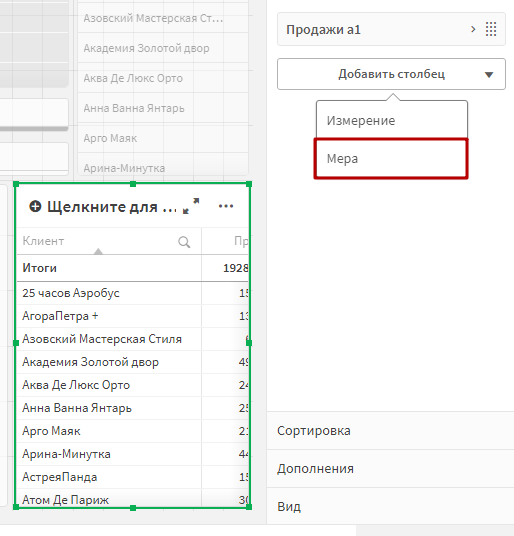
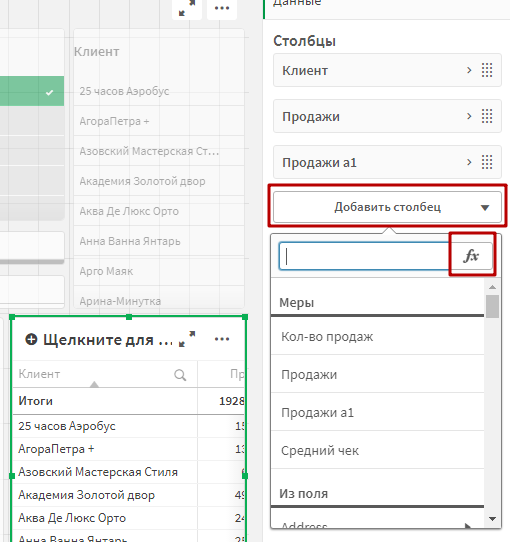
В редакторе выражения пропишите формулу:
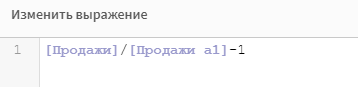
Напомню, что если мера сохранена как основной элемент, мы можем использовать ее навание в других формулах, без необходимости прописывать выражение заново.
Теперь, делая отборы по разным фильтрам в разных состояниях, вы будете видеть сравнение результатов в %.
Взаимодействия множеств. Фильтры в разных состояниях с единой основой. Анализ исключенных элементов.
Возможность выбирать произвольные комбинации фильтров для сравнения очень интересная. Но согласитесь, было бы удобно сначала задать общую основу фильтрации, а в ней уже выбрать набор фильтров 1 и 2.
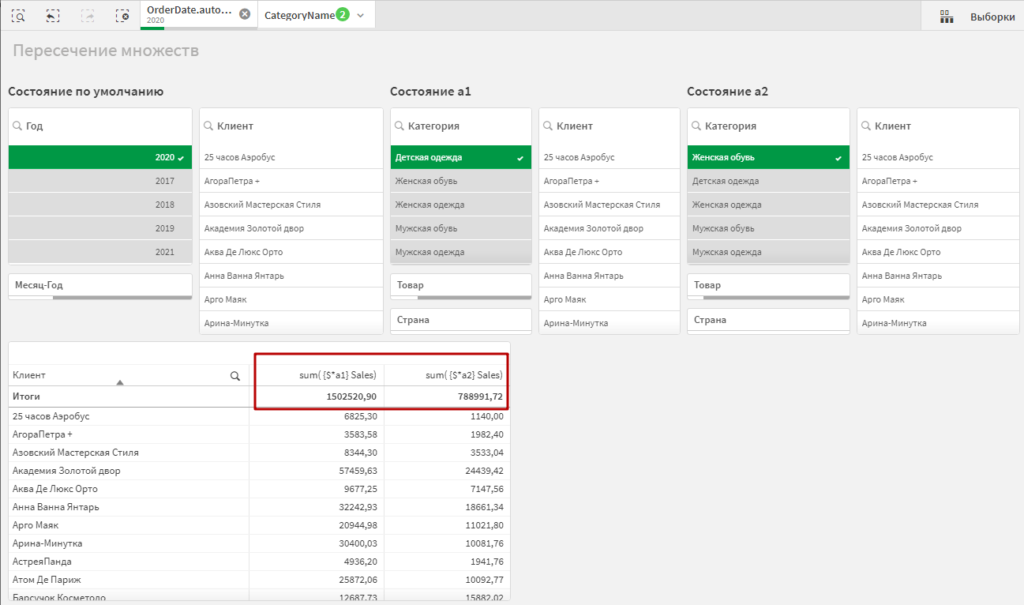
Создайте новый лист со следующими элементами:
- Новый блок фильтров в состоянии по умолчанию, с измерениям Год, Месяц-Год, Клиент;
- Скопируйте блок фильтров в состоянии a1 с предыдущего листа;
- Создайте альтернативное состояние a2 и разместите копию блока фильтров в состоянии a1, назначив ему состояние a2;
- Создайте внизу обычную таблицу с измерением Клиент.
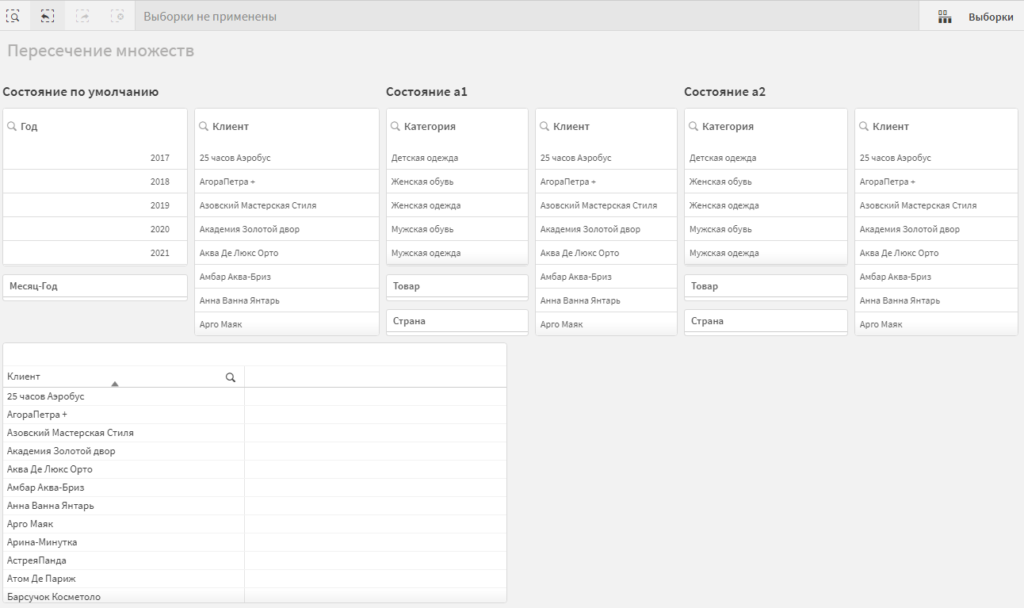
Создайте в таблице новую меру, и пропишите в нее формулу: sum( {$*a1} Sales)

Разберем конструкцию. Знак $ внути фигурных скобок означает текущую выборку в состоянии фильтров по умолчанию. Т.е. те фильтры, которые устанавливаются, когда мы не создаем никаких альтернативных состояний. «a1» — это уже знакомое нам альтернативное состояние фильтров. Знак «*» между ними означает пересечение значений.
Т.е. если в состоянии 1 выбраны Категории А и Б, а в состоянии 2 выбраны Б и В, то выражение будет отфильтровано по Б.
Разберем возможные действия на этом примере:
- + (объединение, $+a1): применится фильтр А,Б,В
- — (исключение, $-a1): применится фильтр А, т.к. значения фильтров Б и В будут исключены.
- / (исключение общих, $/a1): применится фильтр А и В, т.к. исключаются значения, общие между множествами.
- * (пересечение общих, $*a1): Применится фильтр Б, как общий между множествами.
По такой же логике, создаем вторую меры в табилце: sum( {$*a2} Sales).
Теперь вы можете увидеть, что при установке фильтров в состоянии по умолчанию, оба выражения реагируют одинаково.
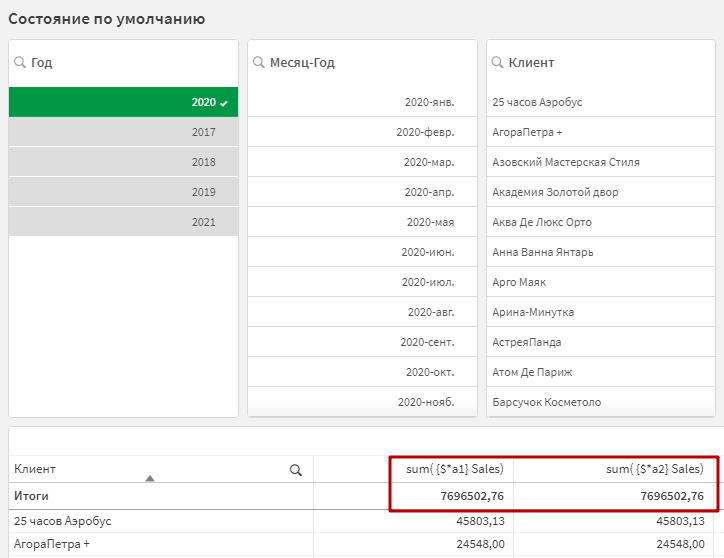
Но, если активировать фильтры в других состояниях, то значения начнут отличаться. Т.е. мы сначала задали общую основу для анализа первым фильтром, а потом разделили темы анализа фильтрами в других состояниях.
Можно быстро попробовать еще одно выражение: count (distinct {1-$} Product). Единица олицетворяет собой все данные нашей модели. Соответственно, конструкция 1-$ покажет нам данные по набору фильтров, которые были исключены текущей выборкой.
Разместите его в простой таблице с измерением Товар. Теперь, если выбрать в фильтре перечень клиентов, то вы увидите писок товаров
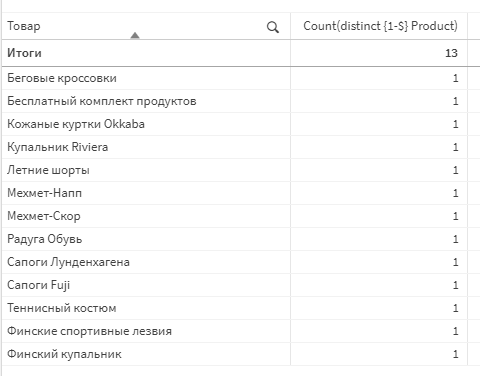
Заметьте, что пока не выбран ни один фильтр, таблица ничего не покажет. Потому что если фильтре не установлен — значит выбрано все, а когда вы исключаем все из всех данных, ничего не остается.
Данная функицональность называется анализ множеств (Set Analysis), более глубоко мы разберем ее в отдельных занятиях. Но вы уже на своем опыте убедились, что даже с базовым подходом она дает большую свододу исследования данных, выходящую за пределы линейной фильтрации.
Благодаря ассоциативному движку, мы можем задействовать в аналитике не только те данные, которые пользователь отфильтровал, но и те, что оказались за пределами фильтров.
Это позволяет видеть полную картину с меньшим количеством действий и усилий.
Выводы
- Альтернативные состояния позволяют создать универсальные механизмы для операций сравнения;
- Используя анализ множеств и операторы взаимодействия множеств, можно создать логику поведения фильтров
На этом базовый курс закончен. Посмотрите разел мини-курсов, чтобы изучить другие темы.
Евгений, спасибо. Сначала начал изучать Qlik по марафонам datayoga, но теперь только ваши курсы.
Опечатки: Выбериет, умлочанию, отфлиьтровал
sum( {$*a2} Sales). не работает, ошибка в формуле
Проверьте, что у вас создано альтернативное состояние a2 или то, что в формуле регистр букв и наименования у моделей и состояний полностью соответствуют тому как это прописано у вас в модели данных. Убедитесь что не включено лишних фильтров. Или скачайте мой итоговый файл и посмотрите что отличается в вашем решении.
Все формулы работают, и на скринах это видно 🙂 Если у вас не работает, значит вы где-то отклонились от курса.