Проходите актуальную обновляемую версию этого курса на учебном портале
Скачайте учебную таблицу, на которой мы будем тренироваться.
Создайте в Loginom новый пакет, перейдите в раздел Сценарий.
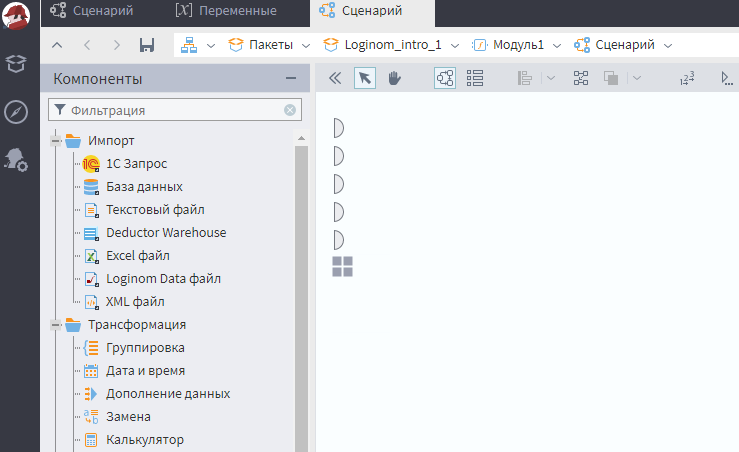
Из блока Импорт перетащите узел «Текстовый файл». Вообще, все элементы, из который строится сценарий, называются «узлы».
Пара слов об узлах
Каждый узел представляет собой определенную операцию, выполняемую над данными. Данные перемещаются между узлами через порты.
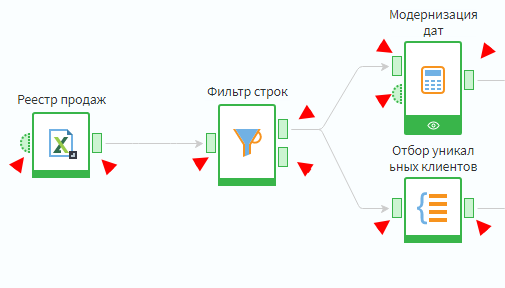
Прежде всего, порты делятся на входные и выходные. Входные порты располагаются на узле слева, и принимают данные, на базе которых будет работать обработка внутри узла. Справа располагаются выходные порты, в которые передается результат выполнения узла. Порты могут быть разных типов в зависимости от структуры передаваемых данных. Варианты могут быть следующие:

В 90% случаев вы будете оперировать табличными данными или переменными. Состав и обязательность портов определяется в зависимости от функций конкретного узла. Необязательные узлы выделяются пунктиром.
Также, внутри портов работает такой аспект, как Синхронизация. Это значит, что внутри входного либо выходного порта можно определять, какое кол-во полей пойдет в дальнейшую обработку. Либо какие поля входного массива данных будут сопоставлены с перечнем полей, ожидаемых узлом.
Этот функционал широко применяется для переиспользования компонентов. Например, когда вы сделали некий сценарий, который требует на входе какие-нибудь 3 определенных поля. Например, сумма продажи, дата продажи, клиент. Но таблица, которую вы собираетесь подать на вход, имеет:
- Другие названия этих полей;
- Дополнительных полей помимо тех трех, что нужны.
С помощью функционала синхронизации вы сможете завести в узел только те 3 поля, что нужны для его выполнения. И сопоставить их с целевыми ролями. Мы более подробно рассмотрим это в будущем занятии. А пока, вернемся к нашему сценарию.
Простейший сценарий обработки данных
Мы добавили на экран наш первый узел — импорт текстового файла. Чтобы загрузить данные, нам потребуется настроить узел. Это можно сделать, щелкнув ЛКМ по узлу, а затем на шестеренку. Либо вызвать контекстное меню узла с помощью ПКМ, и выбрав соответствующий пункт.
Укажите путь к файлу. Не будем фокусироваться на деталях настройки кодировки и отступов. Для этого вы можете почитать официальный мануал. Либо применить накопленный опыт :).
Настройки каждого блока даются в виде последовательности экранов, которые можно переключать через точки внизу, либо стрелками слева и справа от центральной области.
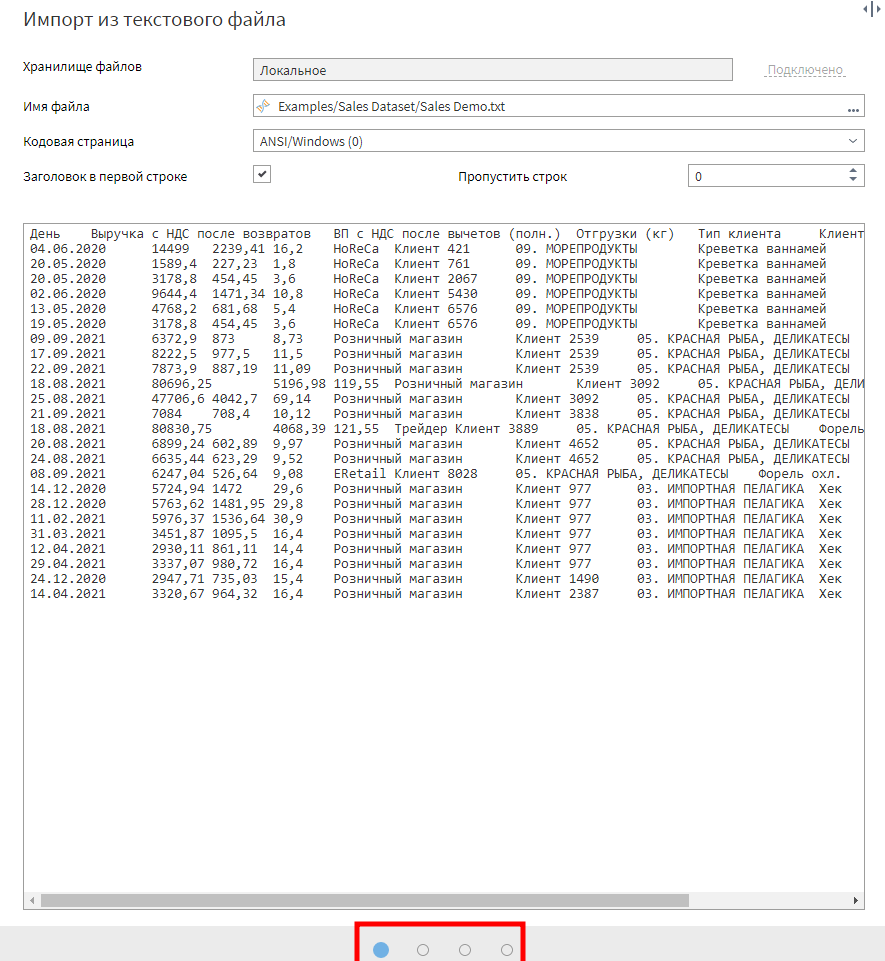
На что нужно обратить внимание при импорте данных? Во-первых, каждая колонка имеет настройку типа находящихся в ней данных (разработчики Qlik горько вздохнули в этот момент :)). Во вторых, поля имеют Имя и Метку. Имя — техническое название поля, которым вы будете оперировать в формулах. Рекомендую избегать в именах полей символа «.». Метка — человекопонятное имя, которое будет выводиться при просмотре данных и в визуализациях.
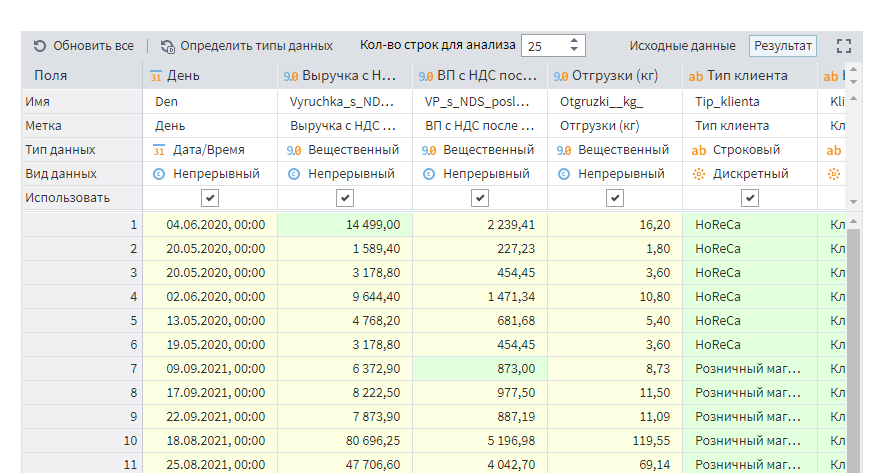
При настройке загрузки вы можете увидеть, как значения раскрашиваются в цвета. Зеленый цвет значит полное соответствие данных выбранному типу. Желтый — частичное соответствие. Т.е. вроде соответствует, но мало ли что. Красный — несоответствие. Попробуйте задать полю Тип клиента тип данных Число, и посмотрите что будет. потом верните все как было.
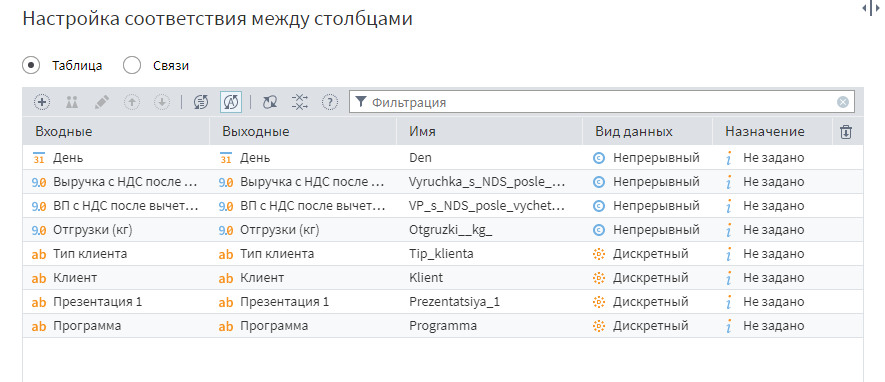
Следующий экран — настройка соответствия между столбцами. Именно тут и настраивается синхронизация, о которой мы говорили раньше. пока оставляем все как есть
Финал настроек — ввод названия узла и его описания. Обязательно пользуйтесь этим функционалом, чтобы сделать схему сценария более читабельной.
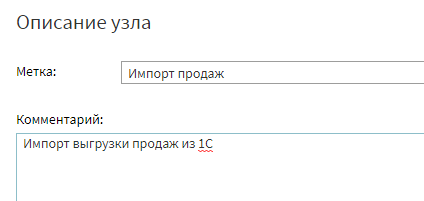
Комментарий будет виден в т.ч. во всплывающей подсказке на схеме. Его можно скрыв, кликнув по кавычке, из которой он «вылетает». Заголовок узла также можно поменять двойным кликом на имени узла на схеме, не заходя в настройки.

Нажмите на кнопку выполнения сценария. Узел окрасится в зеленый цвет, что свидетельствует о его успешном выполнении.
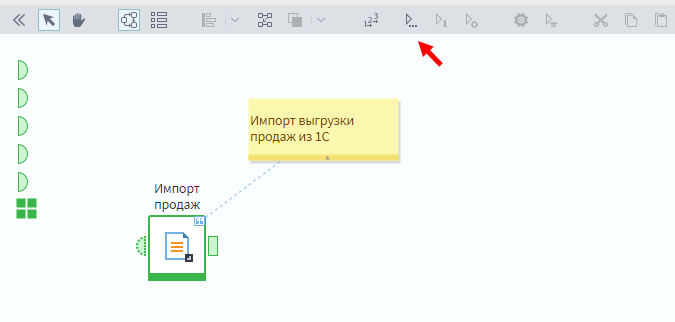
Вы можете выполнять узлы отдельно, что полезно на этапе отладки. Для этого надо нажать кнопку выполнения непосредственно на самом узле.
Если кликнуть ПКМ по выходному порту, то можно активировать быстрый просмотр итоговой таблицы. Либо, можно 2 раза кликнуть по порту ЛКМ.
В отличие от превью в момент импорта, этот просмотр позволяет видеть все данные таблицы (привет Qlik Sense с предпросмотром 50 первых строк в модели данных).
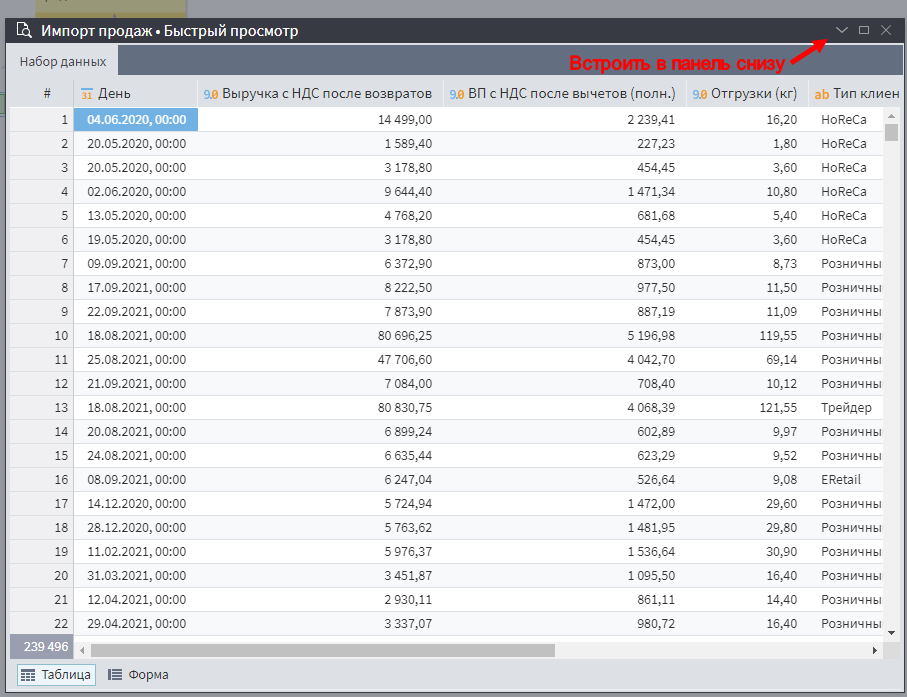
Можете нажать на кнопку сворачивания предпросмотра, чтобы он не перекрывал схему сценария, а отображался в доп. панели внизу экрана.
Добавим узел Фильтр строк. Красный цвет входного порта означает, что в нем не выполнены настройки, необходимые для выполнения узла.
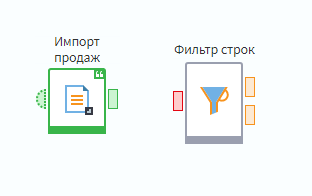
Свяжем результат импорта со входом фильтра, и зайдем в настройки узла Фильтр.
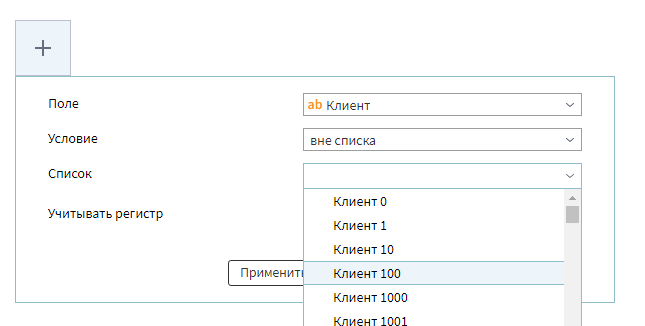
Давайте настроим условие фильтра: поле Клиент вне списка, и выберем значение Клиент 100.
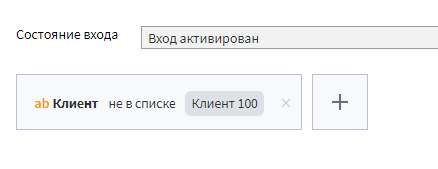
Выполним сценарий и посмотрим, что там на выходных портах фильтра. У фильтра есть 2 выходных порта. В первый попадают данные, удовлетворяющие критериям фильтрации, во второй — неудовлетворяющие. Посмотрите и убедитесь, что из второго порта выходит таблица, где записи относятся только к клиенту 100.
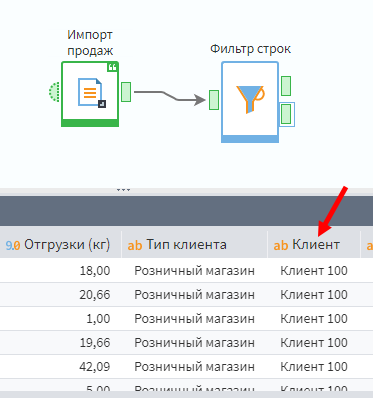
Вопрос от бдительных разработчиков: это что, после фильтрации, мне посчиталась в т.ч. часть данных, которую я хотел отбросить, и потратила ресурсы ЭВМ? Ответ: нет. Потому что вычисления происходят только при наличии запроса. А запрос этот формируется:
- Либо узлом, который будет принимать данные из соответствующего порта;
- Либо запросом на просмотр содержимого порта.
Поэтому при «боевом» выполнении сценария отфильтрованные данные действительно исчезают. Если только они не используются другим узлом.
Давайте финишировать занятие. Добавьте из раздела Экспорт узел Loginom Data File, соедините первый выходной порт фильтра со входным портом экспорта. Выполните сценарий.
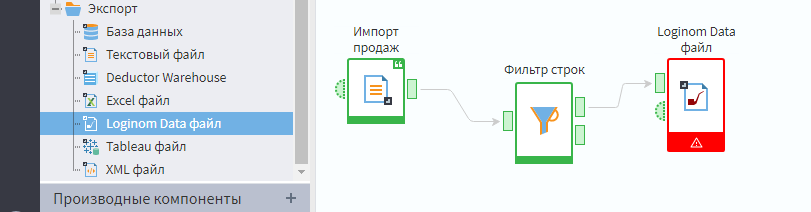
Вы получите сообщение об ошибке, а сам узел окрасится в красный цвет. При том что входной порт будет зеленым. Это значит что с входными данными все ок, но внутри самого узла что-то не настроено, либо присутствуют ошибки. Ну еще бы, ведь мы не настроили путь сохранения файла.
Задайте желаемый путь сохранения, и выполните сценарий.
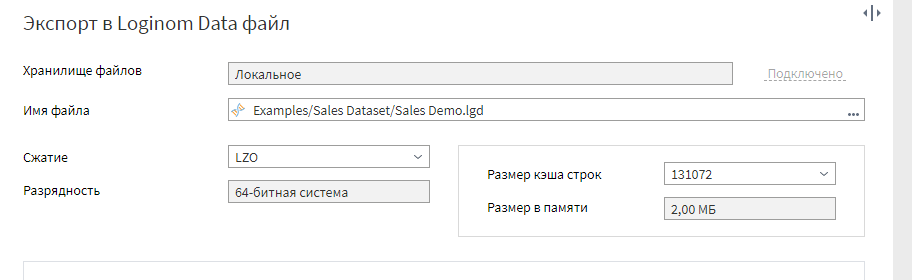
Теперь вы можете наглядно сравнить, в чем выгода использования lgd файлов для хранения дата-сетов с целью использования в Loginom. По сравнению с исходником, он вести почти в 5 раз меньше, на нашем примере. Да, мы отфильтровали немного строк в ходя занятия. Но разница всеравно впечатляет. Кроме того, загрузка из lgd файлов происходит намного быстрее, чем из других источников. Как я и говорил раньше, по сути это аналог qvd файлов в Qlik.

В следующем занятии мы разберем, как улучшить управление ходом выполнения сценария с помощью переменных.