Содержание
- Загрузка данных;
- Правила разметки имен полей;
- Правила и рекомендации подготовки данных;
- Параметры генерации модели;
Загрузка данных
Данные загружаются в приложении с помощью скрипта загрузки. Для этого они должны быть размещены между секциями скрипта —SSM Sub— и —Call SSM—.
На итоговую модель влияет 2 фактора:
- Набор таблиц и разметка имен в загружаемых таблицах;
- Настройка параметров генерации моделей во вкладке !!! Main Settings !!!
Вы можете использовать тестовые данные для тренировки.
Базовая разметка имен полей для загрузки данных
Создайте новую секцию скрипта между —SSM Sub— и —Call SSM—, и добавьте туда следующий код (скорректируйте источник загрузки таблиц в соответствии с вашими настройками приложения).
Сделки|@i_leadID:
LOAD
LD.Сделка,
@i_leadID as @i_leadID|L,
"LD.Дата создания" as "LD.Дата создания|D",
@i_contactID as @i_contactID|L,
@i_responsibleUserID as @i_responsibleUserID|L,
LD.Бюджет,
"LD.Откуда клиент",
"LD.Целевой/не целевой",
"LD.Дата закрытия" as "LD.Дата закрытия|D",
@LeadPositionID as @LeadPositionID|L
FROM [lib://Files/SSM Training/Сделки.qvd]
(qvd);
Контакт|@i_contactID:
LOAD
CN.Контакт,
@i_contactID as @i_contactID|L,
@i_companyID as @i_companyID|L,
"CN.Дата создания" as "CN.Дата создания|D"
FROM [lib://Files/SSM Training/Контакты.qvd]
(qvd);
Компания|@i_companyID:
LOAD
CM.Компания,
@i_companyID as @i_companyID|L,
@i_responsibleUserID as @i_responsibleUserID|L,
"CM.Дата создания" as "CM.Дата создания|D",
CM.Регион
FROM [lib://Files/SSM Training/Компании.qvd]
(qvd);
Убедитесь, что у вас выставлены следующие параметры генерации модели на вкладке !!! Main Settings !!!:
vSSM_DropHash,0
vSSM_Qualify,0
vSSM_QVD_Buffer,
vSSM_Restore_Links,1
vSSM_ANum_CK,1
vSSM_AccCalMode,D
vSSM_AsOfDate,1
vSSM_DynPeriods,1Обратите внимание что у таблиц и некоторых полей присутствуют параметры, прописанные через вертикальную черту. На их основе определяется структура построения модели.

В названии таблицы обязательно должен быть указан первичный ключ данной таблицы. Он не обязан быть уникальным для каждой строки. Если для данных в таблице отсутствует «настоящий» первичный ключ, то его можно сгенерировать двумя способами:
- Сгенерировать поле с помощью функции rowno() (нумерация строк таблицы);
- Создать составной ключ, как комбинацию всех полей связи и полей дат, которые планируются к использованию.

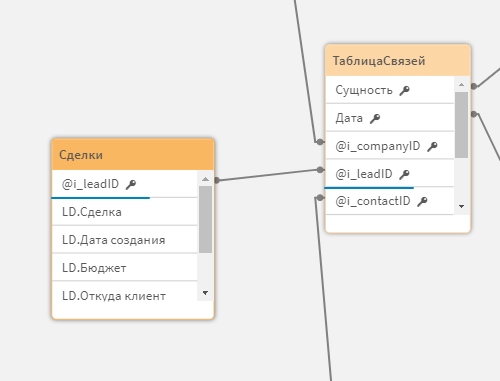
Поля, которые планируется использовать для связи с другими таблицами, нужно отмечать меткой «|L». Названия таких полей должно быть одинаково во всех таблицах. Т.е. если мы хотим использовать для связи поле @i_contactID в сделках, то оно должно аналогично называться и в контактах.
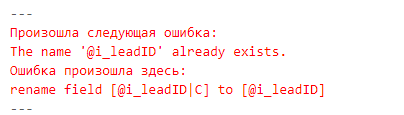
❗Нельзя использовать метку «|L» для поля в одной таблице, и иметь аналогичное поле без данной метки в другой таблице. Например, в одной таблице вы указываете поле «@i_contactID|L» с меткой для связи, а в другой оставляете @i_contactID без этой метки. Это приведет к ошибке выполнения скрипта из-за невозможности переименовать «@i_contactID|L» к исходному значению, потому что такое поле уже будет существовать в модели.
❗Обратите внимание, что ваши сгенерированные первичные ключи тоже должны быть отмечены меткой «|L». Иначе это приведет к неправильной работе модели и, возможно, генерации таблицы связей на десятки или сотни миллионов лишних строк.
При генерации модели создается каноническая временная ось. С ее помощью вы сможете на одной временной оси анализировать данные из разных таблиц. А также если в одной таблице содержится несколько типов дат. Например, можно сопоставлять плановые и фактические данные. А также анализировать данные по разным сценариям. Например, суммы счетов на даты выставления или оплаты.
Для добавления поля даты в каноническую временную ось, нужно использовать метку «|D».
❗Генератором моделей будут обработаны только те таблицы, в которых есть поля с символом «|». Таким образом вы можете добавлять в загрузку среди прочих таблицы, которые не будут участвовать в генерации.
После выполнения сгенерированного скрипта таблицы и поля вернутся к исходным именам. Загрузите данные из примера.
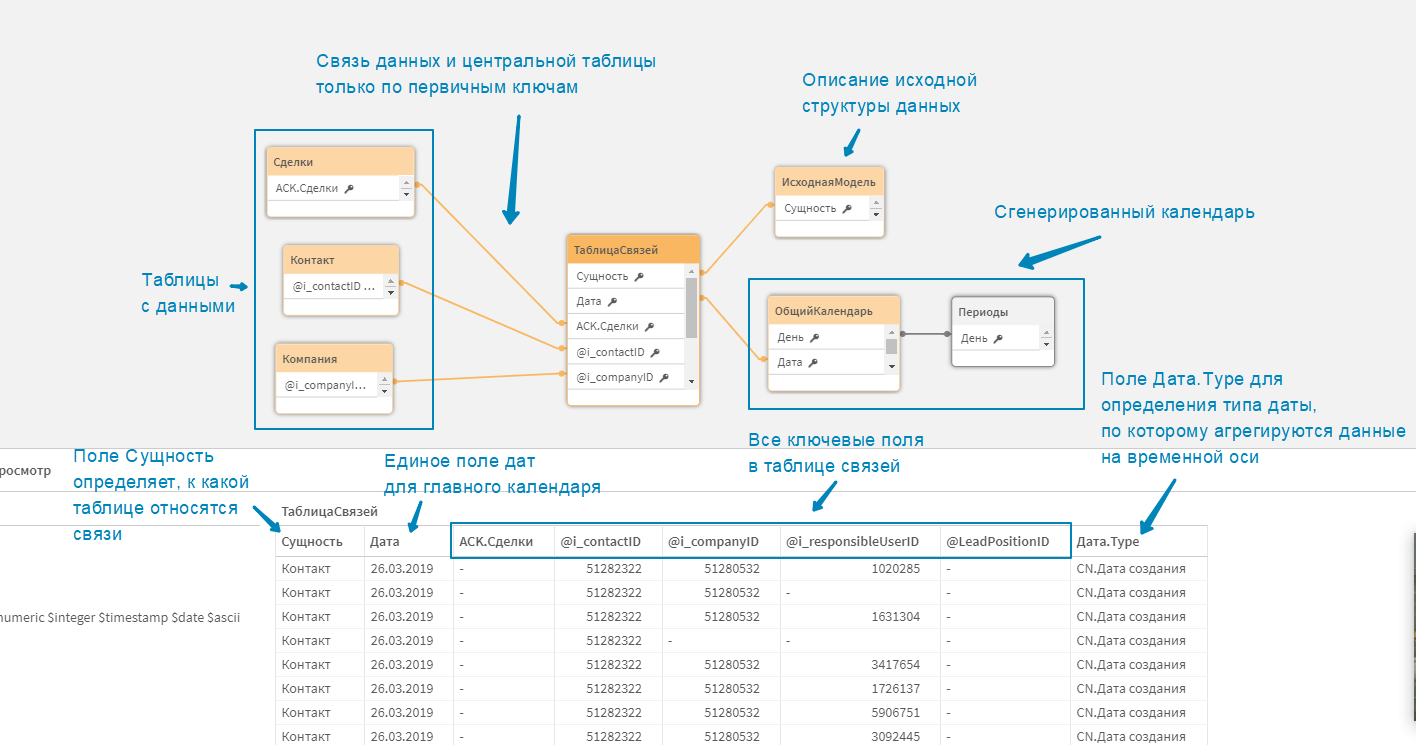
Структура итоговой модели
Правила и рекомендации подготовки данных
✓Все преобразования данных выполняйте в отдельных приложениях, сохраняя чистовые таблицы в QVD. В генератор загружайте только чистовые таблицы без какой-либо обработки.

✓Заранее позаботьтесь о том, чтобы в ваших чистовых таблицах все поля, которые не используются для связи, имели уникальные названия на уровне всех таблиц, которые у вас есть. Поля, которые используются для связи, наоборот, должны иметь одинаковые названия во всех таблицах. Также, для них неплохо указывать какой-нибудь спец. символ, типа «@». Хотя в генераторе есть функция автоматической квалификации, с ростом кол-ва таблиц будет удобнее, когда они изначально корректно размечены.
✓Все отсутствующие значения в полях связей и полях дат для канонического календаря должны иметь значение Null(). Часто бывает, что отсутствующие данные в полях такого рода могут быть отмечены как пустота (»), или как 0, или как ‘N/A’ или что-то еще. В случае полей связи, это приведет к созданию неверных связей, т.к. все эти варианты будут восприняты как еще одно значения поля. В случая с календарем, такие даты могут быть интерпретированы как что-то вроде 31.12.1899, что приведет к генерации избыточных значений в календаре. А если вы используете календарь накопительного итога, это может критически удлинить время выполнения скрипта.
✓Поля, которые используются для канонического календаря, должны быть приведены в формат даты (без меток времени). Это можно проверить, посмотрев на теги поля в модели данных. Там обязательно должны быть $date и $integer

✓Если вы хотите связать на временной оси данные с разной детализацией периодов (например, факты продаж, идущие по дням, и плановые данные, разбитые по месяцам), то в таблице, где данные идут по более крупным периодам, нужно преобразовать обозначения периодов в дату, соответствующую первому числу периода. Т.е. для месяцев — первая дата месяца, для кварталов — первая дата квартала и т.д. Таким образом данные успешно сложатся на канонической временной оси, и вы сможете отображать их с нужной детализацией через измерения календаря.
Параметры генерации модели
В секции скрипта !!! Main Settings !!! расположен список параметров генерации модели. Часть из них относится к генерации таблицы связей, а другая часть — к генерации календаря. Сейчас разберем параметры генерации модели.
vSSM_DropHash: 1 или 0, 0 по умолчанию. Если стоит 1, то на стороне сервиса удаляется сгенерированный код модели данных для данного набора таблиц и параметров, и происходит его повторная генерация. Требуется в некоторых сценариях технической поддержки. Нет надобности активировать этот параметр самостоятельно — придется каждую перезагрузку ждать до минуты генерацию кода.
vSSM_Qualify: 1 или 0, 0 по умолчанию. Автоматическая квалификация имен полей, которые не используются для связи. Полезная функция, если вам нужно быстро построить модель с большим кол-вом полей с неразмеченными именами. Однако, при этом используется повторная перезагрузка данных из всех таблиц с данными через resident load, что удлинняет время выполнения скрипта. Рекомендуется использовать при первичном исследовании данных с неразмеченными именами полей, но в будущем лучше провести разметку имен, и отключить эту функцию для ускорения загрузки.
vSSM_QVD_Buffer: устаревший экспериментальный параметр, не трогайте его.
vSSM_Restore_Links: 1 или 0, 1 по умолчанию. Восстанавливает связи между таблицами, связанными не напрямую. Работает по следующей логике: если в таблице есть поле связи, не являющееся первичным ключом, которое является первичным ключом в другой таблице и имеет поля связи, отсутствующие в первой таблице, то эти поля будут присоединены в таблице связи к записям первой таблицы. И далее эта проверка проводится по отношению ко следующему уровню связи.
Этот механизм отлично работает со связями один-ко-многим и не приводит к дублированию данных в исходных таблицах. Восстановление связей проводится для каждой таблицы модели с учетом всех остальных таблиц модели.
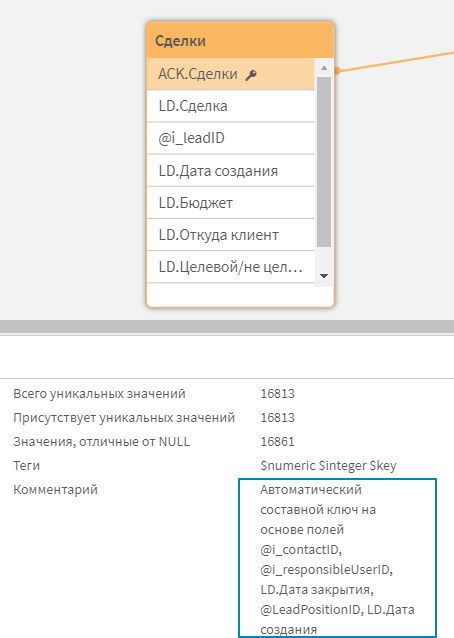
vSSM_ANum_CK: 1 или 0, по умолчанию 1. Если генератор моделей видит, что первичный ключ таблицы не используется как ключевое поле в других таблицах, то оно заменяется автоматически сгенерированным составным ключом, включающим все ключевые поля и поля канонического календаря данный таблицы. Это позволяет сократить кол-во записей в таблице связи, без ущерба для логики связей. Активация данного параметра обрабатывает значения в получившемся поле функцией autonumber(), для сокращения длины составного ключа в целях оптимизации производительности. Если параметр равен 0, вы увидите оригинальные значения составного ключа.
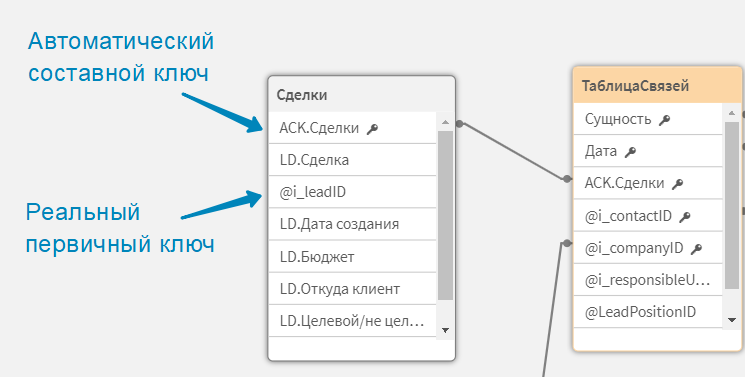
У автоматических составных ключей создается комментарий, описывающий, на базе каких полей он создан.
Вы можете отключить автоматическую генерацию составных ключей у отдельных таблиц, используя на первичном ключе метку «|C». Этот прием рекомендуется использовать, когда вы уверены, что данное поле не будет использовано как ключевое поле в других таблицах. Например, если это изначально составной ключ, и его повторная генерация не требуется.
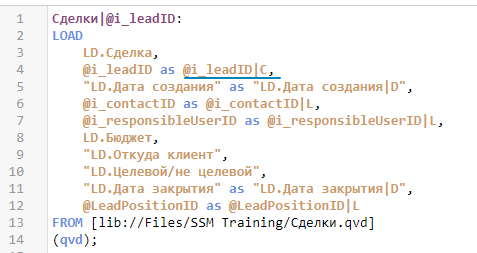
Учитывайте, что поле с меткой «|C» может быть в модели в единственном экземпляре. Т.е. нельзя задать параметры генерации, где есть @LeadID|C в одной таблице и @LeadID|L в другой — вы получите ошибку при выполнении сгенерированного кода о том, что нельзя переименовать одно из полей, т.к. заданное поле уже есть в модели.